
type
status
date
slug
summary
tags
category
icon
password
Property
Jun 2, 2024 12:46 PM
Created time
Mar 30, 2024 01:44 PM
1. 这是本人的毕业设计,因时间紧迫以及个人专业素养低等原因,可能存在逻辑表达不通顺、废话连篇、行文错漏等情况。
2. 本人仅承诺该设计在实验工作和直接运行结果上的真实性,至于对结果展开的讨论是否可靠则不能完全保证。
3. 本文直接转自论文的word文档格式,尽管进行了适应性调整和校对,但仍可能存在一定的格式错乱。
4. 因尚未征得当事人同意,我对致谢中的相关人名进行了隐去。
摘 要
近年来,基于端到端的模型结构成为语音识别领域最热门的研究重点。然而,端到端语音识别方法的优秀性能依赖于大量语料数据,这对世界上现存的众多缺乏标注数据的低资源语言并不友好。目前已有不少研究尝试借助迁移学习技术帮助提升低资源语言下的语音识别效果。本文的主要工作如下:
1)提出了一种改进的低资源汉语方言语音识别模型。通过结合迁移学习的预训练模型微调技术,基于端到端思想的混合CTC/Attention架构模型,并改进为使用双向注意力机制的Transformer解码器模块,实现了以多领域粤语语料库(MDCC)为源语言数据集,以福州方言为迁移学习目标语言的低资源汉语方言语音识别模型构建工作。模型以福州方言专用音标(榕拼)为目标输出序列,在总计73.6h的源语言数据集及2.48h的目标语言数据集上进行建模,得到了6.6%的字错率(CER)和27.3%的词错率(WER)结果。
2)设计实现了一套汉语方言语音识别系统。利用移动Web相关技术栈,构建了具有音频语料收集校注功能及模型部署投入应用的小程序平台。完整实现了包括“采集—训练—部署”工作在内的汉语方言语音识别工作。
关键词:端到端语音识别;迁移学习;低资源;注意力机制
Research of Automatic Speech Recognition Based on Transfer Learning with Low-Resource Fuzhou Dialect
Abstract
In recent years, end-to-end speech recognition techniques have become a hot research focus in speech recognition. However, the excellent performance of end-to-end speech recognition methods relies on a large amount of corpus, which is unfriendly to the large number of low-resource languages existing in the world. Several studies have been conducted to improve this problem through transfer learning. The work of this paper is as follows:
- Constructed a speech recognition model for low-resource Chinese dialects with a hybrid CTC/Attention end-to-end architecture, combining fine-tuning method of transfer learning on pre-training model, and improving its Transformer decoder using a bidirectional attention mechanism. The model uses the Multi-Domain Cantonese Corpus (MDCC) as the source language and the Fuzhou dialect as the target language for transfer learning. The model was trained on a total of 73.6h dataset of source language and 2.48h dataset of target language with Fuzhou dialect specific phonetic symbols (Yngping) as the target output sequence. Performance test has shown a CER of 6.6% and a WER of 27.3%.
- Built a mini-app with functions of audio corpus collection and model deployment based on mobile web technology stack, which means this work has been realized a complete system of Chinese dialect speech recognition task of collecting, training and deploying.
Key Words: end-to-end speech recognition; transfer learning; low resources; attention mechanism
1 绪论
1.1 课题背景
语音识别(Automatic Speech Recognition, ASR)技术用于将人类语音音频内容转换为计算机可读的输入,通常转换为可理解的文本内容。作为一项融合多学科知识的前沿技术,语音识别在人机自然交互和自然语言处理技术中扮演着关键的角色。随着近年来深度学习端到端技术的不断发展,语音识别模型性能得到了极大的提升,为人们的日常生活提供了许多便利。
然而,受限于语音数据获取和标注困难且耗时昂贵等难点,当前语言识别技术的运用主要局限于资源丰富的主流语言,如英语和汉语普通话。在世界范围内仍存在着大量标注数据稀缺的低资源小语种,如何在这些语言上构建有效的语音识别模型成为该领域近年来的研究热点。
迁移学习(Transfer Learning)是一种能够学习一个或多个类似任务中的知识,并借助所学知识完成对相似新任务的快速构建的方法。大量使用深度学习相关技术的语音识别研究指出,语音特征的深度表示都蕴含在其声学模型或与之功能类似结构的每层输出中,这种特征表示隐式地提取了人类语音在声学层面的共性。通过调整预训练所得原有的网络参数,可以容易地将这些特征迁移运用到其它语种的声学模型中。借此技术,低资源条件下的语音识别任务能够而获得更加稳健的声学模型[1]。目前已有大量基于迁移学习的小语种语音识别研究成果被发表。
以闽、粤等地为代表的汉语南方方言使用者基数大,而这部分方言与汉语普通话音系存在较大差异,传统针对普通话训练的语音识别模型无法在方言场景下通用,这在实际应用中形成了大量汉语方言语音识别的功能需求。另一方面,大多数汉语方言存在与世界各地小语种类似的低资源困境,这类方言常存在书写系统不完善,语言环境式微的情况。常规的大规模音频语料采集并标注工作难度很大,公开数据稀缺。
因此,研究汉语方言语音识别技术能够迎合社会环境广泛需求,对方言相关产业发展与保护工作具有较大的现实意义。同时,将迁移学习技术应用于汉语方言语音识别建模工作可充分利用现有丰富资源语言的语料库,提升模型产出的准确性、可靠性。事实上,方言语音识别建模与迁移学习相关领域的许多细节问题,如汉语音系独特的声韵调结构相较以其他无调语言在迁移工作中的影响等尚未被更多研究测试验证,该领域仍有具有较大的理论发掘空间与研究意义。
1.2 国内外研究现状
1.2.1 语音识别算法
从研究方法上看,语音识别建模一般依赖大量的标记音频/文本数据来进行监督学习。目前普遍存在的数据集短缺问题致使半监督或无监督学习方法成为算法研究层面的热门。
在框架设计上,基于端到端的模型架构成为主流。端到端(End to End)语音识别模型主要以连接时序分类(CTC)和基于注意力(Attentiion)的编码器—解码器(Encoder-Decoder)结构为两大实现方法。在自注意力机制的思想指导下,不少先进性能表现的模型算法被提出,如Transformer,Conformer,Branchformer等。
与此同时,许多以语音识别为核心任务的工具包开源项目被提出,用以改善传统语音识别建模工具环境搭建复杂、调试改进困难的问题。 2018年,ESPnet团队提出了ESPnet工具框架[2],这是当前最活跃的语音开源社区之一,可基于端到端模型实现语音识别、语音合成、语音增强等多项任务。该工具包内部实现了CTC,Transformer, RNN-T等多种算法模型,被越来越多的国内外研究项目所使用,此外,该框架也提供了有关迁移学习的相关支持。
1.2.2 迁移学习技术
迁移学习技术的研究方向主要为特征空间、监督信息、迁移方法和在线方式。目前,迁移学习技术基本包含三大类实现方法:样本权重迁移法、特征变换迁移法和预训练迁移方法。其中,在源领域实行有监督学习,而目标领域实行无监督学习的领域自适应(domain adaption)课题是迁移学习的最热门的一个分支。
在语音识别领域,预训练模型微调(fine-tune)这一传统迁移学习手段仍然是大部分研究工作的测试重点。2021年,侯汶昕等人发表的研究[3]将基于适配器(Adapter)的迁移学习方法带入到语音识别中。相比于全模型微调,该方法仅使用了5%的可训练参数,但是相对词错率(WER)能够降低3.55%,获得了良好的性能表现。
1.2.3 汉语方言
近年来国内发表有关使用迁移学习技术的语音识别相关研究中,语音识别建模的目标语种选择以蒙古语[4]、维吾尔语[5]、彝语[6]等少数民族语言为主,契合了迁移学习在低资源小语种上的优势特点。这些研究的迁移学习工作主要使用来自普通话和英语的公开语料库作为源语言预训练建模材料。
目前涉及汉语方言的迁移学习语音识别技术研究文章较少,国内现有相关研究工作有相当一部分局限于方言点[7]或方言类别[8]的划分任务。这从侧面能够反映出音频标注语料资源匮乏问题阻碍了完整语音识别工作的展开。
在已发表的使用普通话为迁移学习源语言的语音识别研究成果中,目标语言主要是粤语和闽南语这两个影响力大,资源相对丰富的汉语方言。Jian Luo等人2021年发表了一系列跨语言的迁移学习语音识别工作测试结果[9],其中使用AISHELL-2数据集作为普通话预训练模型建模语料,以IARPA Babel粤语数据集来建模目标语言模型。相较从头开始训练的模型,经过微调模型实现了5.45%的提升。
1.3 研究内容
结合现有问题与实际应用场景,以低资源汉语方言中的福州方言为例。本设计课题围绕以下几个关注点展开设计研究:
- 设计一套可靠简便的语料收集校注和模型构建部署系统;
- 比较不同算法对低资源汉语方言语音识别的建模效果差异;
- 测试迁移学习对低资源汉语方言语音识别的提升效果;
- 尝试对现有主流模型算法进行改进。
1.4 组织结构
本文主要分为以下几个部分:
第一章为绪论部分,首先阐述研究的相关背景与意义,而后整理相关文献,对其概括总结,在语音识别算法、迁移学习技术和具体到汉语方言应用领域分析相关研究的现状,并提出了整体的研究内容。第二章主要对本文研究所使用到的技术方法进行介绍,包括端到端语音识别技术现有主流算法中的CTC和注意力机制,ESPnet的建模框架,迁移学习常用方法以及小程序相关技术原理。第三章主要对语料收集及模型部署平台构建,预训练及其微调等系统的设计方法进行了说明,并专门解释了双向注意力模型改进的原理方法,同时简要介绍了评价指标。第四章按照第三章的设计思路,对相关任务进行了实现。完成了小程序前后端的搭建工作。进行了预训练和微调模型的构建,并对性能结果进行了分析。使用双向注意力与重打分机制修改模型构建源码,对其改进后的建模结果开展性能研究。最后结论部分对本文的相关研究进行总结并对后续工作进行展望。
2 相关技术
2.1 端到端语音识别
传统语音识别建模常分为声学模型与语言模型两大任务板块,任务间借助发音词典的信息相互串联。端到端语音识别模型则直接以通过特征提取的语音向量为输入,以文字序列为输出,内部主要使用深度学习技术,省去了发音词典和各项中间环节,有效减少了预处理和后处理工作,使得训练流程更加简洁。对分阶段学习流程的规避使得模型学习时具有更大的灵活性,加大了模型依从训练数据而自我调节的空间。此外,基于端到端的模型源码大都具有良好的结构可调性,利于算法改进相关研究。
目前端到端的语音识别模型主要有两种常见的实现,其中一种是由Alex Graves等人提出的连接时序分类(Connectionist Temporal Classification,CTC)方法[10]。另一种是基于注意力机制(Attention)的编码器-解码器(Encoder-Decoder)模型。
2.1.1 连接时序分类(CTC)
CTC方法是对RNN的一种改进。传统RNN模型对两个序列映射进行建模时要求一一对应。但是语音数据通过特征处理分帧后序列长度非常大,对应文本序列长度一般很短,这使得RNN对其映射困难。
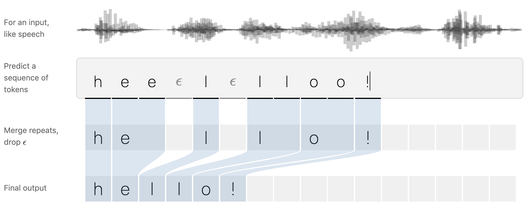
CTC引入了一个特殊的空字符<blank>,通过在任意两个字符之间插入<blank>并允许字符重复出现,CTC可以构造出从声学特征到字符之间所有可能的对齐路径,并且以最大化所有对齐路径的似然概率之和作为训练目标[10]。借此可以直接将以时间划分的语音帧序列自动地在模型训练过程中与其相应的转录文字序列对齐,不需要在连续语音中参照模型设定的最小分词单位标注出现的起止时间段,免去传统算法在数据时域上较为复杂的切分和强制对齐操作。
但是CTC方法在结构上假设了条件独立性,这使得该模型假设每个输出在条件上独立于给定输入的其他输出,无法利用上下文信息帮助预测。因而单纯的CTC模型性能并不理想,常需要增加语言模型或其他结构以提高性能[11]。
2.1.2 注意力机制(Attention)
注意力机制在编码器-解码器的神经网络结构中扮演着重要角色。编码器将经过预处理的输入序列转换成固定长度的高维隐含向量,该过程主要承担内容感知与特征提取工作。然后解码器再利用编码器的输出向量信息解码为目标序列。而基础注意力机制相关算法沟通了编解码过程,能够考虑当前解码位置与编码器得到的隐含向量的相关性,并赋予相应的权重。通过该行为,注意力机制能够聚焦输入信息的某个特定区域,得到更细节的信息,从而更好地建立起解码器输出特征与编码器各个序列输入的高维隐含表示之间的关联[12]。
注意力机制通过整个输入特征计算相关性,并对其进行加权求和,从而获得相关信息,指导输出标签的解码,该过程在计算流程上不需要对齐操作。而语音信息是具有强烈时序关系的典型数据类型,无需对齐的模型算法可以很好地对这种关系进行建模,因此,注意力机制克服了语音识别中最基本的难题之一,具备比循环神经网络(RNN)和卷积神经网络(CNN)更强的上下文建模能力[13]。
2.1.3 Transformer模型
Transformer模型由Google和多伦多大学在2017年提出[14]并以其良好的序列到序列(seq2seq)建模能力,逐渐成为语音识别中的主流模型。
图 2.2展示了Transformer模型的基本结构,包含N个编码器块和N个解码器块。 每个编码器都有三个核心操作层,分别是多头自注意力机制、归一化处理和前馈层;而解码器相较于解码器在归一化处理与前馈层之间增加了使用编码器—解码器信息的多头注意力层。注意力层带有残差连接,可以实现跨层的信息传递。层的激活值会通过归一化处理,从而解决梯度爆炸和梯度消失的问题,加快模型的训练过程和收敛速度。
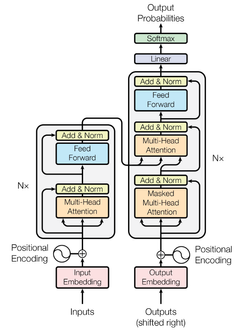
该模型核心同时用到了注意力机制和自注意力(Self-Attention)机制。自注意力机制是注意力机制的一个变体,注意力机制主要用于处理两个不同序列之间的关系,而自注意力机制则更适用于处理单一序列内部的位置关系。以文本翻译为例,在一句话中,注意力机制着眼于当前翻译的单词与原文本序列每个部分的关系强度;自注意力机制则使每个单词关注同序列中其他单词的关系信息(主谓,指代等)。
在自注意力机制的流程中,输入向量X将与代表查询(Query)、键(Key)和值(Value)的三个权值矩阵WQ、WK、WV相乘,分别得到Q、K、V。
Q和K通过内积计算相互间的关联,该过程得到的结果数值会伴随维度一同增长,为了加强正态分布,使得反向传播时获取更平衡的梯度,计算结果将除以特征维度的开方,然后通过softmax()操作将相关性输出归一化,然后求取V的加权和得到结果。完整的计算公式如下[12] [14]:
其中dk是Q,K矩阵的列数,Bi为注意力机制的第i行输出结果,对应输入序列中某一帧Xi的注意力信息。每个帧位置Xi总是将其他帧Xj的信息一并包含在计算过程中,这使得整个序列的上下文信息都能包含在当前位置的输出中。训练注意力机制的过程实际上是在对权值矩阵WQ、WK、WV进行优化与更新。
Transformer模型在现有语音识别任务中表现良好,基于编码器—解码器结构特点,可独立、拆分或与其他模型组合实现端到端语音识别,通常不使用语言模型就可以获得较高精度的识别性能。但是Transformer模型因其复杂的层叠式结构带来了巨大的参数量,常需大量数据集来驱动整个模型内部参数的调整优化,否则容易产生过拟合现象。
2.1.4 Branchformer模型
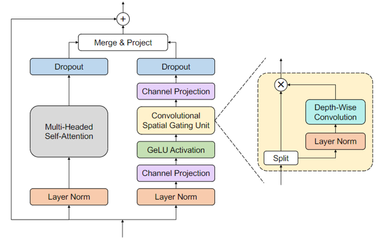
Branchformer模型是彭祎帆等人于2022年提出的编码器方案[15]。图 2.3展示了该模型的核心结构,每个编码器块具有两个并行分支,一个分支使用自注意力或其变体来捕获全局关系,而另一个分支使用带有门控卷积的多层感知器(cgMLP)模块来提取局部关系。Branchformer编码器结构灵活,在可解释性和定制性上表现较好,在大量ASR 和 SLU 基准测试中的表现都大大优于传统Transformer和cgMLP。它还实现了与最先进的Conformer模型相当或更优越的性能,同时在极端数据条件下的训练效果更加稳定。
2.1.5 混合CTC/Attention 模型
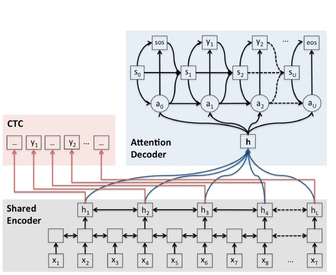
ESPnet工具在语音识别任务中的模型结构主要参考自Shinji Watanabe等人研究的混合CTC/Attention方法[16]。该方法有着通用的编码器—解码器框架,其中,经过语音特征提取的输入序列将进入一个共享编码器中得到一个蕴含语音声学信息的固定长度编码向量。该共享编码器算法是可被定制的,目前ESPnet支持VGG-like CNN 、BiRNN (LSTM/GRU)、Transformer、Conformer、Branchformer在内的多种编码器结构。编码向量将分别进入CTC模块与注意力解码器模块分别得到解码序列,在训练和实际解码过程中,两个模块的输入结果会进行加权计算损失或得分,以优化模型或得到最终解码结果。目前被支持的解码器算法包含RNN (LSTM/GRU)、Transformer等。这种联合解码
方式表现出相当优秀的性能,并引导大量相关模型和项目开发工作。
2.2 迁移学习
预训练模型微调是迁移学习工作中最常用的一种方法,该方法首先在大规模数据进行训练,以学习模型的通用特征表示。通常针对有标注数据实行有监督学习,而存在大量未标注数据时采用半监督学习或无监督学习技术,后者是目前研究工作的热点[17]。预训练的目标是使模型能够捕捉数据中的潜在模式和结构。而后开展微调工作,这将在特定任务的有标记数据上使用预训练模型的参数作为初始权重,通过有监督学习的方式对模型进行微调,以适应任务特定的要求和数据分布。先前预训练模型已经学习到了丰富的特征表示,可以为目标任务提供更好的初始化参数,从而加快模型的收敛速度并提高性能。
微调策略的设计是微调方法中的核心问题。主要包括冻结与解冻层、学习率调整和正则化等方面的考虑。冻结与解冻层策略可以根据目标任务的相似性灵活选择是否冻结模型的某些层。学习率调整可以通过逐渐减小学习率的方式实现,以平衡预训练模型和目标任务之间的知识转移。正则化技术可以有效防止过拟合,提高模型的泛化能力。
2.3 小程序
小程序是一种轻量级应用程序,它们通常运行在移动操作系统的专用平台上。其本质是通过使用跨平台技术,将应用程序的核心逻辑和界面元素封装在一个独立的Web容器中,以实现在移动设备上的快速加载和交互体验。小程序开发涉及HTML/CSS布局样式、JavaScript交互逻辑、组件库和搭载平台API框架等前端技术,后端技术包含服务端API接口设计与数据库管理等。
小程序相较于传统软件具有无需繁复的安装流程、快速加载和响应、跨平台支持、便捷分享和传播、实时更新和版本控制等优势[18]。这些优势有助于在语料收集和模型测试工作中降低开发成本,提升工作效率。
2.4 本章小结
本章主要介绍了课题研究涉及的各项技术信息,包括CTC和注意力机制在内的端到端语音识别方法、迁移学习微调方法的原理过程、小程序开发技术的特点。重点介绍了注意力机制及其代表模型Transformer的核心实现,为后续研究工作提供原理指导。
3 系统设计
3.1 训练材料与输出目标
语音识别工作首先需要明确模型训练数据集的具体类型以及目标输出结果,这将指导整个工作的设计与优化过程。了解课题研究所涉及语言材料的特点,有助于加强以任务导向的针对性,提升最终产出模型的性能。
3.1.1 福州方言的特点
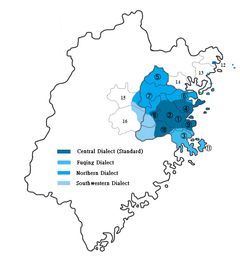
福州方言常称福州话、平话,是汉语族闽语支闽东语的代表方言,属闽东语侯官片,为福州民系的母语。福州方言主要通行于闽江流域中下游至入海口,涵盖11个县市,这些地区都属于昔日的福州十邑。
福州方言(市区标准音)的独立声母有15个,韵母46个,声调7个。
表 3.1展示了福州方言中辅音音位的国际音标记法与榕拼(福州方言专用记音方案)转写。
表 3.1 福州方言中的辅音
ㅤ | 双唇 | 双唇 | 龈 | 龈 | 软腭 | 软腭 | 声门 |
爆发音 | p | b | pʰ | p | t | d | tʰ | t | k |g | kʰ |k | ʔ | h或k |
塞擦音 | ㅤ | ㅤ | t͡s | z | t͡sʰ | c | ㅤ | ㅤ | ㅤ |
鼻音 | m | m | ㅤ | n | n | ㅤ | ŋ | ng | ㅤ | ㅤ |
拍音 | ㅤ | ㅤ | ɾ | l | ㅤ | ㅤ | ㅤ | ㅤ |
擦音 | ㅤ | ㅤ | s | s | ㅤ | ㅤ | ㅤ | h | h |
近音 | β̟ | w | ㅤ | ɹ | j | ɹ̃ | nj | ㅤ | ㅤ | ㅤ |
边近音 | ㅤ | ㅤ | l | l | ㅤ | ㅤ | ㅤ | ㅤ |
注1:分割竖线“|”左侧为国际音标,右侧加粗的符号为榕拼。
注2:上表中 /ɾ/, /β/, /ɹ/, /ɹ̃/ 为仅在连读时出现的新声母
表 3.2展示了福州方言元音(基础韵母)音位的国际音标记法与榕拼转写。
表 3.2 福州方言中的元音
ㅤ | 前元音 | 前元音 | 后元音 | 后元音 |
ㅤ | 不圆唇 | 圆唇 | 不圆唇 | 圆唇 |
闭元音 | i | i | y | y | ㅤ | u | u |
中元音 | e | e | ø | eo | ㅤ | o | o |
低元音 | a | a | ㅤ | ㅤ | ɒ | oo |
表 3.3展示了福州话的7个声调在五度标调法下的表示方式
表 3.3 福州方言中的声调
调类 | 上平 | 上上 | 上去 | 上入 | 下平 | 下上 | 下去 | 下入 |
五度 | 55 | 33 | 21 | 24 | 53 | ㅤ | 242 | 5 |
福州话相对普通话音系更加复杂,音节组合数大。此外,福州方言在语流中会发生机制复杂的松紧变韵、声母类化、韵尾类化和连读变调,为其他方言所罕见。以词汇【蕹菜】为例,使用榕拼进行表记,其单字读音依次为oung21 cai21, 而在语流中将变化读为ung53 njai21。这使得福州话语流中汉字读音多变,且各个口音区变化规律差异很大。
现代福州方言的正式书写系统一般为汉字(常称福州话正字),但是由于旧社会群众文化程度与识字率偏低,现代社会方言使用环境式微,福州话正字运用环境未能得到充分发展。这使得福州方言文本语料长期以来处于匮乏状态,以福州话正字写就的长文本内容(包括口头对话,正式文书与小品)非常少。与此同时,各方面乡土教育缺失的现状不仅使得大量福州方言使用者不会认读福州方言特有正字,也同时不知晓以普通话文本或文言文本中的许多常用汉字在福州方言中的正确读音。
目前有少数方言保育志愿者参与福州方言的保护与推广的基础工作,完成了部分福州方言文献的电子化工作,由冯爱珍所著《福州方言词典》目前已全部电子化并公开了查询渠道,其中包含有一万多个字词条目,每个条目均收录了单字发音、连读发音及释义。
3.1.2 源数据与目标序列
福州方言目前缺乏公开有效的语音语料库,因此只能自行构建语料收集平台完成音频收集和数据标注工作。考虑到长文本语料同样匮乏的现状,本文仅使用《福州方言词典》中的条目作为计划收集录音的原文本,让发音人参照词典条目念读福州方言词汇读音,校注为目标序列格式,指导模型训练工作。
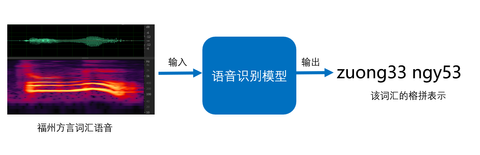
在端到端的语音识别模型中,任务的目标序列一般为该语言的书写文字系统,如普通话常用汉字表记的词句作为目标文本序列。现代福州话的正式书写系统一般也为汉字(常称福州话正字),但本文结合福州方言相关特点、现状以及任务特殊性,决定将语音识别的目标序列定义为使用榕拼描述的福州话词汇记音(如图 3.2所示)。其主要原因如下:
- 文字语料匮乏 福州话现有语料仅词汇表较齐全,以福州话正字写就的长文本数量稀少,且由于缺乏乡土教育,大部分福州话的使用者都处于福州话文盲的状态,对大量福州话正字无法认读。若收集语音使用汉字标记,将大幅提升标注校对难度。
- 充分利用语音信息 在低资源的情况下训练使用汉字作为目标输出进行训练,会导致模型词典庞大而能映射的训练数据稀少的情况。这其中大量的同音字又会被当做完全不同的信息,这使得模型训练能学习到的关联内容变少,效果不佳。而使用榕拼这类的音标表记方式可以充分利用语音资源,因为即使是少量的语音数据,其语音中相同的声韵调成分总是经常出现的。例如:冇[pang21]、跛[po33]、批[pie55]三个字虽不同音,但是声母都相同。这使得模型训练在有限的数据下能学习到更多的信息。
- 语流连读特点 前文所述福州话在连读词汇、句子时的语流会使得单字读音包括声、韵、调在内的整体音系结构发生较大变化,这意味着福州话实际语流中的单个汉字无法像普通话那样拥有基本固定的读音。对模型构建来说,不确定的读音将使得模型训练困难,使用汉字作为目标序列在低资源状态下有较差的预期。
- 迁移学习的领域适应 低资源的语种进行迁移学习时主要采取跨语言下的预训练模型微调实现领域适应,例如使用英语预训练模型微调到捷克语上。对于这部分使用表音字母书写文字的语言,只需将模型训练的分词策略调整为单个字母即可简单地实现领域的基本适应,因为这些字母或字母组合在不同的语言中仍然具有相似或可类比的发音,为迁移学习提供帮助。但是汉语的书写系统特殊,相同的汉字在不同方言之间的读音差异可能很大。如果选择汉字作为输出序列,会使源领域和目标领域差异过大,迁移学习工作难以展开。使用语音到音标类型的表记方式可以规避这种问题,从而改善迁移学习效果。
3.2 系统架构
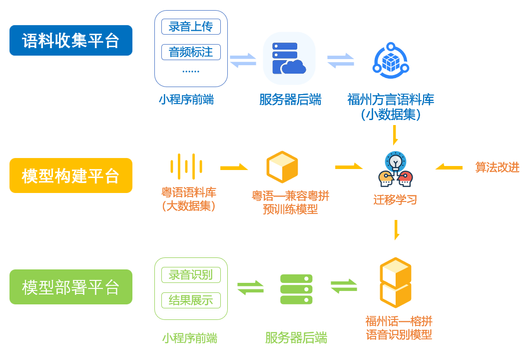
系统主要包含三大模块:语料收集平台、模型构建平台和模型部署平台。各模块之间运行的大体流程如图 3.3所示。其中,迁移学习的模型构建工作是串联起三个模块的核心环节。
3.3 语料收集平台
3.3.1 设计背景
传统的音频语料标注工作常采用招募发音人和审核员统一采集与标注的形式进行,这种方式获取的数据集质量高,但是价格高昂,覆盖范围不够广。近年来,以Common Voice为代表的一些众包项目开始崭露头角。通过向大众广泛征集录音和志愿审核,众包项目能够有效降低相关项目的经济开支,并规避商业风险。另一方面,通过众包项目征集到的录音常带有自然背景噪声,这虽然降低了音频质量,但也能够帮助提高模型训练过程中对语音背景各种环境干扰的适应性,提高模型的稳健性与可靠性。本设计充分考虑了当前大众接入互联网终端类型与常用场景,决定依托微信小程序平台进行语料采集平台设计。尽可能提高平台便捷性与易用性,便于向大众推广与志愿征集。
3.3.2 设计思路
小程序可以简单理解为经由微信或其他主程序API封装的Web交互框架,其大部分特性与移动端的Web网页无异。由此可以使用按照灵活的B/S架构进行开发,用户通过小程序的前端界面交互,向后端服务器发送相关请求,再由后端的API接口处理程序完成相应的决断,并指导后端数据库的交互,从而完整实现功能需求。
前端页面主要完成下述基本功能需求:
- 正常录制用户按照小程序所给文本念读的语音并上传保存至后端服务器;
- 允许用户填写和修改与语料收集工作相关的个人信息;
- 允许具有权限的用户对以收集到的录音进行返听、检查和标注校对。
在实际设计中,增设了欢迎、公告、通知等页面以优化用户体验。
后端的Web框架的运行程序将对来自小程序端的请求进行安全性或身份正确性验证,继而按照请求内容通过连接池与数据库端进行交互,并正确返回操作结果。
后端数据库需要保存的基本信息包括:
- 语料数据贡献者的个人信息 包括验证ID、姓名、年龄段、地域等。尽管目前的语音识别任务并不依赖这些信息,但是这部分信息有助于数据的预处理与筛选;
- 福州方言的文本语料库 提供给音频贡献者念读的方言文本;
- 入库的音频文件信息 记录被上传音频的保存路径,音频来源、标注后的文本以及审核校对的相关情况。
实际设计中,为满足用户登陆需求,增设了一个保存会话信息的基本表。
3.3.3 设计架构
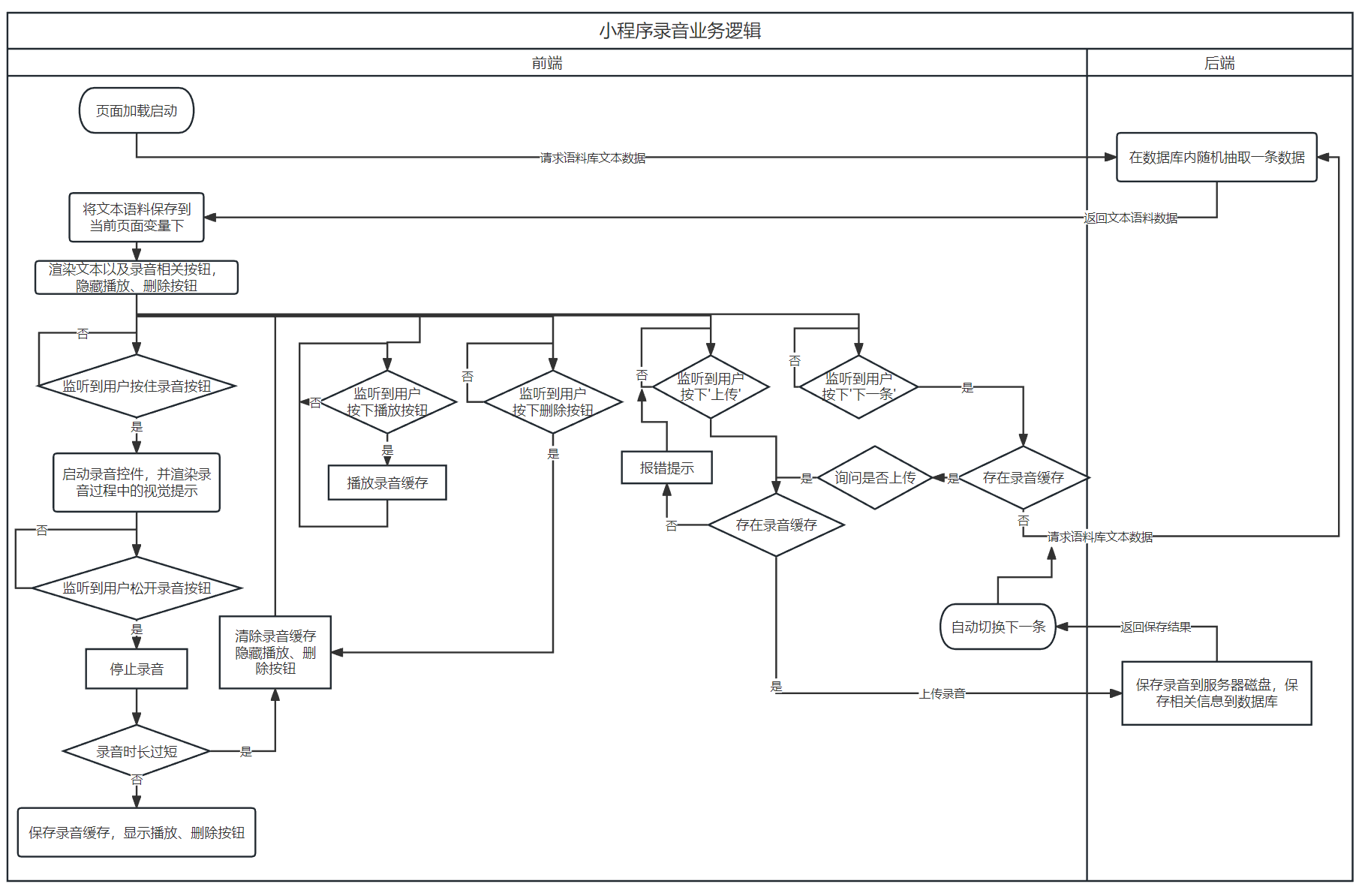
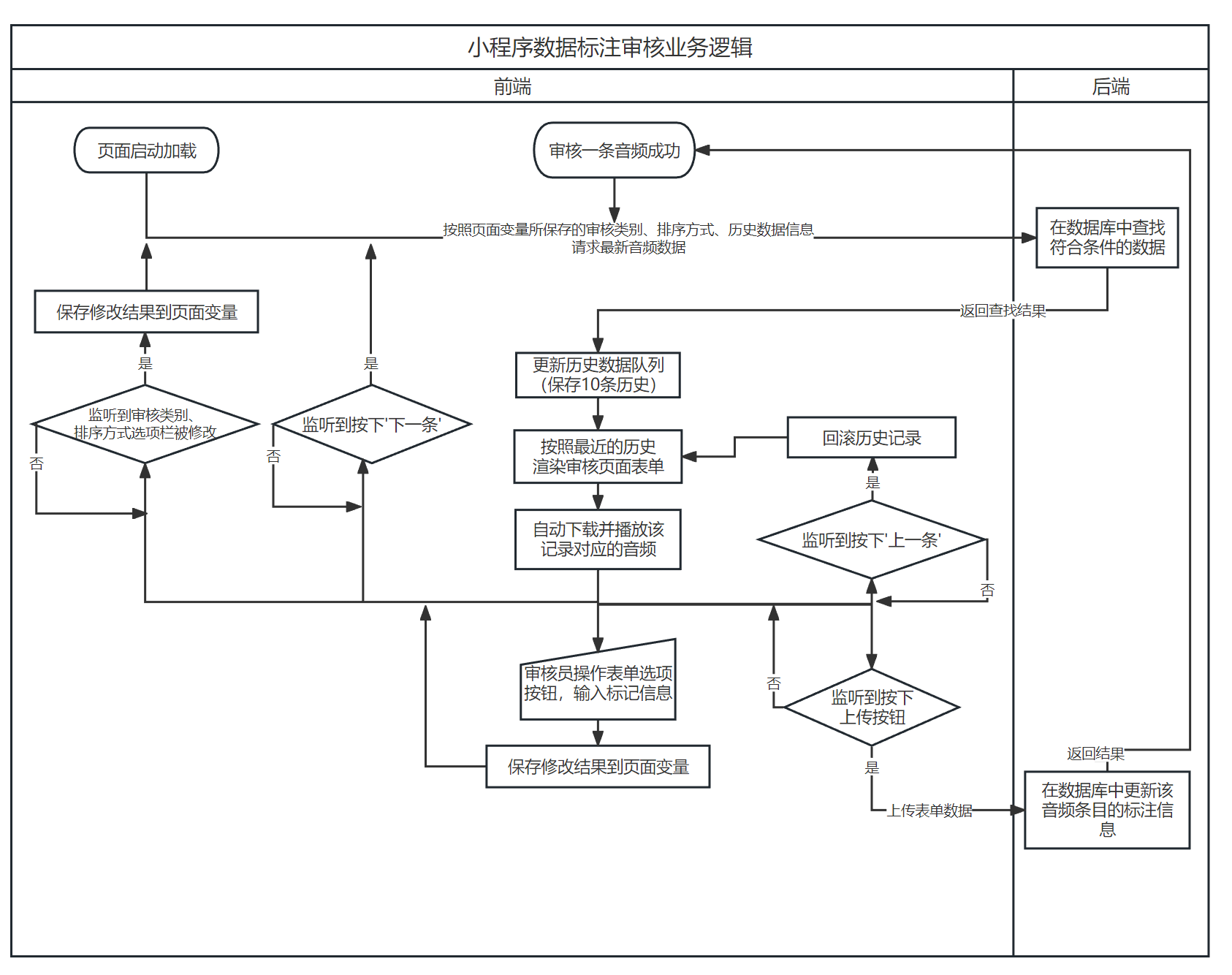
图 3.4, 图 3.5, 图 3.6所示的流程图描述了语料收集平台重要业务的运行逻辑,包括小程序启动登录,录音上传,信息填写和数据审核四块。需要说明的是,除了登录过程外,其余全部HTTP请求均会要求附带启动登录时后端返回的会话号信息,后端在处理请求时首先进行登录验证,提升安全性。
流程图仅能有限地展示各个流程之间的逻辑关系,在项目实现时,受到同步/异步的功能、监听、回调函数等影响,实际的执行顺序可能有所差异。
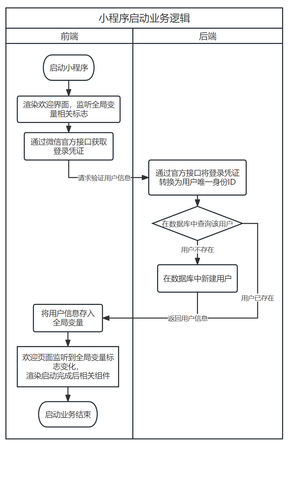
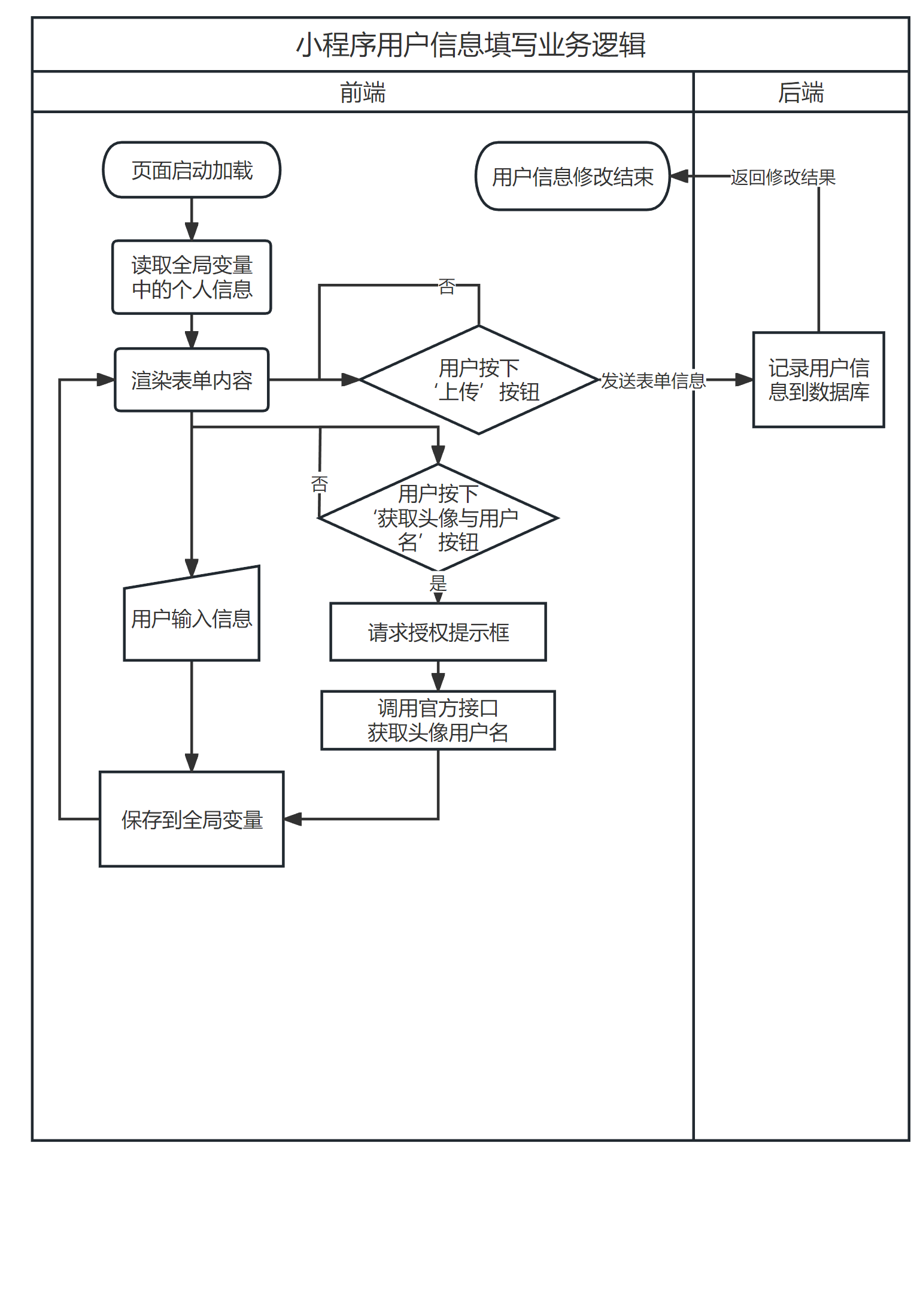
图 3.4 小程序启动(a)和用户信息填写(b)业务逻辑
3.4 预训练模型
3.4.1 语料库的选取与处理
迁移学习所用预训练模型源语言与目标语言的音系越相近,则跨语言迁移学习的领域差异越小,训练效果越好。故本设计尝试在现有汉语南方方言语料资源较丰富的片区进行预训练模型所用语料收集。
香港科技大学相关研究者于2022年公开了多领域粤语语料库(Multi-Domain Cantonese Corpus, MDCC)[13],该语料库从香港的粤语有声读物收集了73.6小时的高质量朗读语音及其汉字转录。内容涵盖了哲学、政治、教育、文化、生活方式和家庭等领域。本设计以此语料库为迁移学习的源语言训练数据。
为适应本设计的任务,MDCC的标记文本需要转写为音标类型。首先通过开源的Rime粤拼词库获取汉字—粤拼的映射,再结合福州方言的音系特点,将粤拼中的部分标记转写或简并,使之提高与榕拼兼容性,修改后的粤拼称“兼容粤拼”。利用这种调整标记序列的方式减小两个语言间的领域差异。其主要变化在于鼻音韵尾、入声韵尾的归并,以及将纯数字标记的声调转写为类福州方言榕拼所用的五度调值。
表 3.4 粤拼—榕拼兼容转写
原粤拼 | 兼容粤拼 | 原粤拼 | 兼容粤拼 | 原粤拼 | 兼容粤拼 |
gw- | gu- | -ung | -oung | -eon | -eoyng |
kw- | ku- | -uk | -ok | -oeng | -oeyng |
yu- | y- | -en/-em/-eng | -eing | -o | -oo |
aa- | a- | -eoi | -eoy | -oi | -ooy |
入声韵尾-p/-t | -k | -on/-ong | -ooung | ||
鼻音韵尾-m/-n | -ng | -ot/-ok | -ook | ||
1 | 55/入声5 | 2 | 24 | 3 | 33 |
4 | 21 | 5 | 24 | 6 | 33/入声2 |
图 3.7展示了将标注数据生成按照ESPnet所要求的Kaldi格式text文件的效果。

3.4.2 模型结构
参照ESPnet所提供的框架结构,使用混合CTC/Attention结构建模,其中共享编码器的注意力机制模型尝试使用Transformer 和 Branchformer两种不同的算法,分别训练两个模型,比较性能差异。解码器处的注意力机制统一采用Transformer算法结构。在实际测试过程中发现尝试加入SpecAugment语音频谱增强方法会出现训练过程损失值异常震荡,无法正常收敛的情况,因此不对语音数据本身进行更多除转码外的预处理。模型解码使用波束搜索(Beam Search)方法,通过CTC/Attention两个解码模块加权评分指导输出序列的推理。
3.5 迁移学习模型
3.5.1 数据集整理
福州方言的语音标注数据主要来自自行构建的语料收集平台,与此同时,福州方言保育志愿团队“真鸟囝”处亦提供了一份极小型的非公开的福州方言词汇念读语音数据集,发音人为一名中年女性福州话播音员,该数据集已经过校对,具有对应的榕拼转写。
本文设计了相关脚本,以从语料收集收集平台的数据库及音频存储位置获取收集到的有效音频文件和对应的标注信息,并与“真鸟囝”提供的数据集合并,统一进行转码和部分标注细节调整,再按比例划分训练集、验证集和测试集,参照ESPnet要求生成Kaldi格式的数据集。ESPnet现有语音识别任务模型并未使用到与发音人个体信息(如年龄,性别)有关的信息,因此不需要强制要求这部分信息的准确性。
3.5.2 模型结构
为降低迁移学习难度,尽可能减少因模型结构不一致造成的训练出错,迁移学习训练过程采用与预训练模型相同的混合CTC/Attention模型结构。因为预训练模型本身的训练数据量并不算庞大,考虑到其对语音特征的学习效果尚不充分,为了在训练过程中更多地利用福州方言语音数据的信息,本文使用全模型微调的方法,有部分观点指出冻结基部的神经网络层后微调对低资源下的语音识别建模有帮助,本文尚未进行更多验证性实验,这部分工作有待日后继续完善。
对预训练模型使用全模型的微调的方法,其基本思想是在ESPnet内加载预训练模型,以此初始化该模型的全部可训练参数,再针对福州方言数据启动适应性训练,适应性训练过程相当于一次普通的模型构建。
这两段之间删去了原本写的以下内容:ESPnet会按照token_list分词词典将标注序列转换为以数字编号token指代的序列向量,这代表了模型在对语音进行识别时搜索的发音词库。不同的分词策略会带来不同的转换结果,例如英文句子“Betty make a better butter”,若以单词为最小单位进行分词,将得到形如“1 0 2 0 3 0 4 0 5”的序列,不同的数字代表了不同的单词(这里0代表空格),整体学习的方式使得模型预测时不会识别出杂乱无意义的单词,但是英文单词库数量巨大,模型空间开销很大;若以音素为最小单位,则有类似“1 0 2 0 5 0 6 0 0 7 0 8 0 9 0 0 4 0 0 1 0 2 0 5 0 3 0 0 1 0 4 0 5 0 3 0 0”的序列,重复出现的数字说明该部分具有相同的实际发音;若以字母/字符为最小单位,将会得到更长的序列,而相对应的模型查询的语言词库就越小,大致为26个字母。
模型迁移过程涉及这些标注序列的映射,在跨语言进行时需要保证两个模型的标注序列转换方法一致,即分词词典一致。为实现粤语和福州方言之间的分词结果兼容,需要手动控制分词方法,以字符为最小单位,并禁止自动生成分词词典,分词方法固定为粤拼、榕拼所用的26个字母(实际上部分字母未被使用),加上五度标调法所用的五个阿拉伯数字。该序列转换结果也将在之后的模型改进工作中使用到。
ESPnet的迁移学习技术指导文档指示了在微调过程加入语言模型的方法,实际测试过程发现在本数据集下语言模型的加入无法提升语音识别效果,甚至出现了负优化问题,因此本处工作不添加包括语言模型在内的各种模型结构修改优化手段。
3.6 评价指标
字错率(Character Error Rate, CER)和词错率(Word Error Rate, WER)是用于评价语音识别模型性能的重要指标,通过衡量识别结果文本与标准文本之间的差异,用以评估模型性能,字错率、词错率越小,说明模型性能越好。
字错率和词错率的计算本质上是一种字符串相似度比对,目前在语音识别领域最广泛接受的算法是引入编辑距离。该算法首先要找到将原字符序列通过多次替换、删除或插入字符的方式编辑为目标字符序列的最优方案(即操作次数最少)。该最优方案可获得以下指标:
S:被替换的字符总数;D:被删除的字符总数;I:被插入的字符总数;
S+D+I的结果称编辑距离,编辑距离可使用动态规划算法实现计算。由此可得字错率的计算公式为:
其中N为序列的全部字符数。词错率的计算思路是相同的,只是将最小编辑单位替换成整个单词。
对于以英文为代表的书写系统,单词是通常是实际语句理解过程的最小单位,因此此类语言的语音识别任务更加重视词错率指标。中文语句中的最小理解单位是汉字,在文本序列以字符的形式存在,并且语言习惯上没有明显的分词标记。因此以汉字为目标输出的中文语音识别任务使用字错率来衡量模型性能。
本文所构建的语音模型输出为音标类型,形式上更接近英语书写系统,字错率指标统计的是逐音标符号之间的差异,词错率指标统计的是以空格分隔的单字音节整体差异。因为训练数据规模小,两项指标均易因训练条件(模型结构,参数设置,数据处理等)的改动产生较大变化,字错率反映模型对语音分帧到最小音位单元间映射的准确度,词错率还反映了模型对记音方案中声韵调结构的理解,因而两者都具有较大的评估价值。
3.7 本章小结
本章描述了语音识别工作大部分环节的设计思路,首先通过对现有研究材料的特点分析,确定语料征集以词汇录音收集为重点,语音模型以类音标的形式作为目标输出。接着描述语料收集平台前后端服务及数据库的功能需求,以流程图的形式给出了业务逻辑设计。而后对语音识别模型的设计进行了说明,包含数据集的处理过程和语音识别建模所采用的算法与结构,及迁移学习工作的一些细节。最后对模型计划使用的性能评估算法进行了介绍。
4 系统实现
4.1 语料收集平台
4.1.1 数据库
后端数据库使用MySQL 5.5.62构建,使用到四个基本表,分别是:
- audio 保存音频数据信息,以唯一的音频文件名为主键,并记录录音时对应的文本映射、标注校对后的榕拼表记,审核通过状态结果,历史审核员,审核备注等信息;
- login 用于登录验证和会话号记录,以唯一的小程序会话号为主键,并记录对应的用户微信ID,用户端微信自分配的会话号,和最后操作记录时间;
- users 用于记录用户信息,以唯一的用户微信ID为主键,并记录用户的上传贡献记录,性别,口音归属,年龄段等信息;
- words 用于保存文本语料库的,这里主要是来自《福州方言词典》的字词数据,包括汉字写法,单字读音,连读读音和释义等信息。该基本表涉及到大量非Unicode基本区汉字,需要开启utf8mb4编码方式才能正常读写数据。此外需要在相应字段使用utf8mb4_bin作为排序规则才能正确返回sql语句中判断条件为部分生僻字符时的比较结果。
4.1.2 API接口
考虑到即时易用性以及与现有大部分深度学习模型构建语言的兼容性,这里使用Python下FastAPI库进行后端web框架设计,这是目前性能最好的Python web框架之一。后端web框架程序启动时与MySQL数据库建立连接池,通过不同的路径操作装饰器依赖项处理不同的http POST请求,主要实现如下接口:
- /GetRandData 随机从数据库的文本语料表words中获取一条记录并返回,用于小程序录音界面的数据刷新;
- /GetSession 对微信官方的登录凭证进行转换,获取用户ID,同时随机生成小程序专用会话号,一并记录到login表内,同时检查是否为新用户,若是,则在user表内新建用户。返回小程序专用会话号。用于小程序欢迎界面的启动登录;
- /Confirm 验证用户数据是否有效,在login内查找请求携带的会话号对应的用户ID ,返回对应的用户信息,用于小程序登录后的信息获取;
- /UpdateUserInfo 更新用户信息,按照请求内容修改users表内的用户信息,用于用户修改页面的数据提交;
- /NewAudio 接收上传录音,保存到服务器硬盘下,并新增相关记录到数据库的audio表,用于小程序录音界面的音频上传;
- /UpdateAudio 按照请求内容修改audio表内记录的审核相关信息,用于小程序数据标注审核界面的审核结果提交;
- /GetAudio 依照请求内容约定的审核状态标记号、数据库记录排序方式、音频记录起点,在audio表内获取所需的音频记录信息。用于小程序数据标注审核界面的音频记录获取;
- /downloadAudio/{filename} 返回音频保存路径下文件名为filename的文件,用于小程序数据标注审核界面的音频文件加载。
4.1.3 小程序
小程序的开发平台基于微信开发者工具 Stable 1.06.2208010,使用Node.js风格的编程语言,并使用了ColorUI开源CSS组件库提升视觉效果。组图 4.1展示了小程序运行时的实际效果:

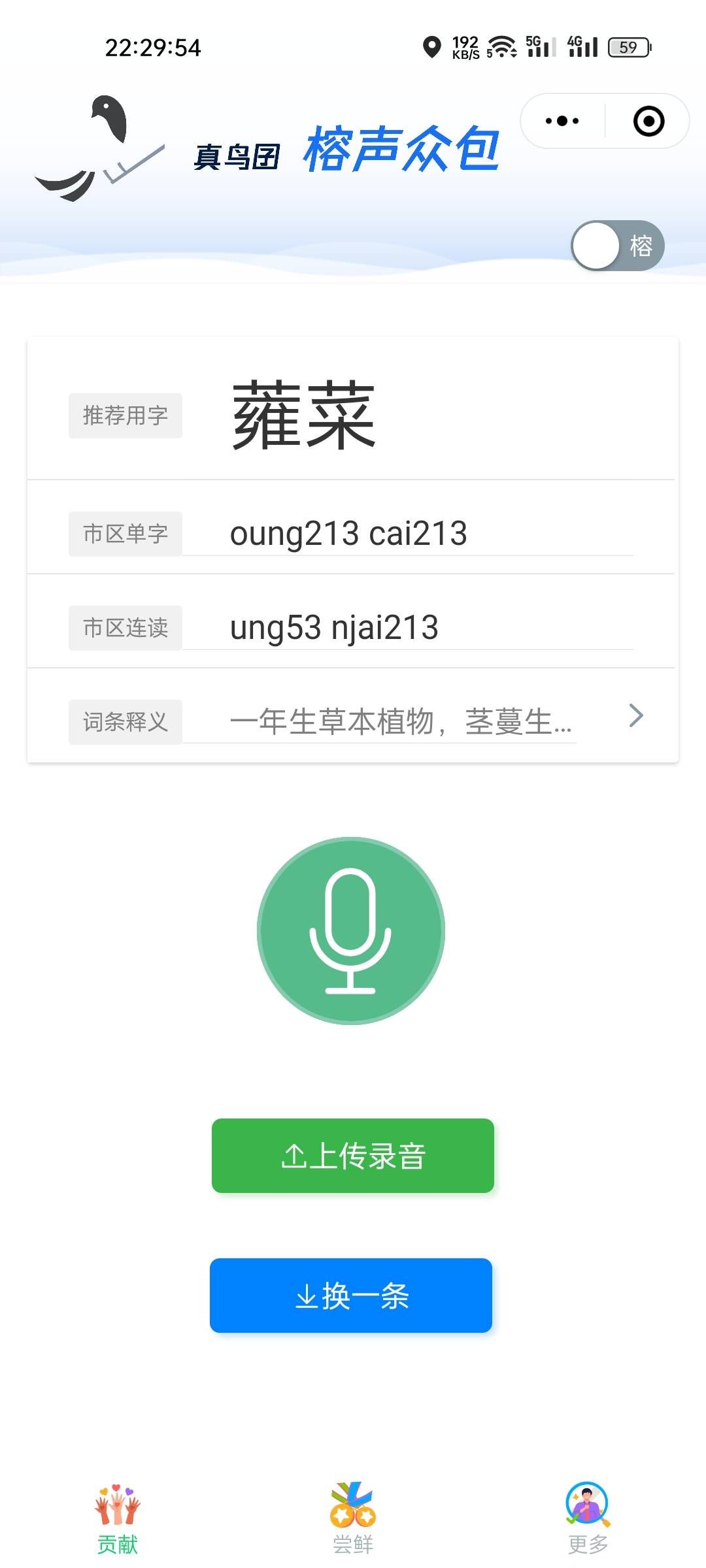
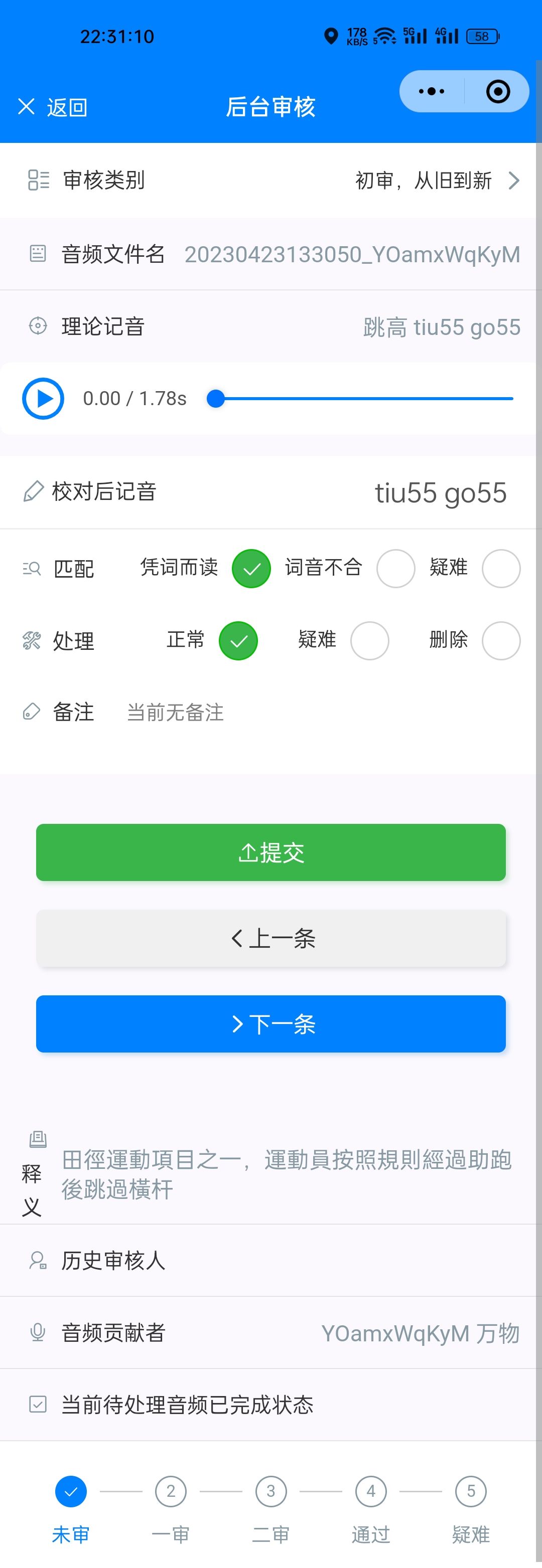
图 4.1 语料收集平台小程序运行效果
4.2 预训练模型
4.2.1 参数设置
MDCC数据集在发布时已预先划分好,本文对划分数量进行了少量调整,最终划分比例为:训练集:验证集:测试集 = 65121 : 9077 : 9077。
训练Transformer共享编码器时,输出序列长度(output_size)设为256;注意力头数(attention_heads)设为4;前馈层随机丢弃比率(dropout_rate)和positional_dropout_rate取0.1;注意力层丢弃比率(attention_dropout_rate)为0;前馈层线性单元数(linear_units)为2048;编码器块数(num_blocks)设为12;开启编码结果归一化;
训练Branchformer共享编码器时,同时开启注意力分支(use_attn)和卷积门控感知器分支(use_cgmlp);输出序列长度(output_size)为256;编码器块数(num_blocks)设为24;注意力机制类型(attention_layer_type)选择相对位置自注意力算法(rel_selfattn);分别设置pos_enc_layer_type和rel_pos_type为rel_pos和latest以充分利用位置信息;注意力头数(attention_heads)取4;卷积门控感知器的线性层单元数(cgmlp_linear_units)为2048;卷积核数(cgmlp_conv_kernel)为31;不在卷积操作后增设线性层;门控激活操作(gate_activation)设为允许完全通过(identity);两分支合并方法(merge_method)选择直接简单合并(concat);丢弃比率(dropout_rate/ positional_dropout_rate/ attention_dropout_rate)统一设为0.1;随机深度比率(stochastic_depth_rate)为0
Transformer解码器端,注意力头数(attention_heads)设为4;前馈层随机丢弃比率(dropout_rate)和positional_dropout_rate取0.1;注意力层丢弃比率(attention_dropout_rate和src_attention_dropout_rate)为0;前馈层线性单元数(linear_units)为2048;解码器块数(num_blocks)设为6,其显式设定的参数与编码器差别不大。
模型训练使用Adam优化算法,该优化算法能够在训练过程中通过学习率衰减来控制沿梯度下降的步长。使用Transformer共享编码器的模型学习率设置为0.005,使用Branchformer共享编码器的模型学习率设置为0.001,训练30次迭代。批次大小设置为16,梯度叠加参数取8,计算损失时CTC权重为0.3。
训练环境为Ubuntu20.04, CPU型号为Intel(R) Xeon(R) Silver 4210R CPU @ 2.40GHz,32G内存,配置1块型号为NVIDIA GeForce RTX 3060内存12G的GPU。采用Python3.8.16作为脚本解释语言版本,Pytorch1.10.0 作为后端神经网络引擎。30次迭代的训练过程在transformer编码器结构上耗时约为5h,在branchformer编码器结构上为13.2h。可以看到branchformer算法带来的训练时间开销较大。
4.2.2 训练结果
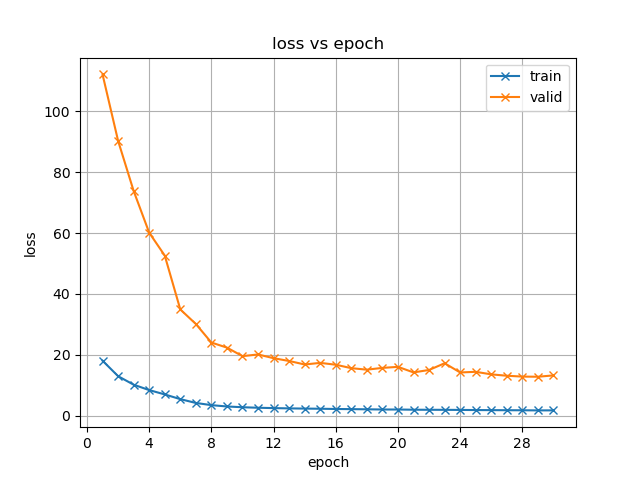
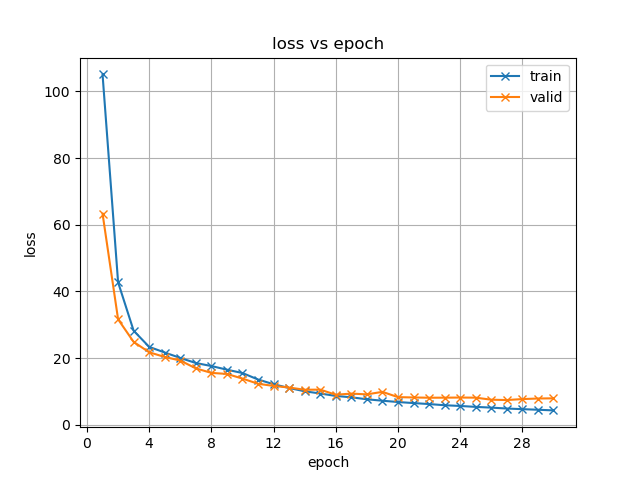
图 4.2模型训练损失值(loss)随迭代次数(epoch)的变化
从组图 4.2可以看出,预训练建模过程正常进行,模型经过迭代可稳定收敛。使用Transformer编码器的模型在约第10次迭代后损失率下降已不明显,但在验证集上的测试性能仍有少量提升。而使用Branchformer编码器的模型在训练起步阶段训练损失值偏大,但是能够随训练进行而迅速下降,使得模型收敛,并且在训练末期仍表现出模型损失值的下降趋势,但验证集(valid)侧似乎有回升趋势,这是模型过拟合的征兆。
表 4.1 不同编码器算法下预训练的性能表现
字错率 CER (%) | 词错率 WER (%) | |
使用Transformer编码器 | 4.4 | 15.0 |
使用Branchformer编码器 | 2.2 | 8.8 |
目前对于一些常见的数据集和应用场景,相关研究报告的词错率常在10%到20%之间。表 4.1是模型在测试集下的性能表现,可以看出两个模型的字错率、词错率性能已达到堪用水准。使用Branchformer编码器构建的模型性能要明显好于使用Transformer编码器构建的模型,这与提出Branchformer结构的论文所述一致。字符级别识别准确度能够达到95%以上也说明训练所用数据集本身质量好,音频条件一致性高,文本转录准确。就结果来说,预训练模型优秀的性能指标为接下来的迁移学习奠定了良好的工作基础。
4.3 迁移学习
4.3.1 参数设置
按照系统设计章节描述的方法对福州方言语音数据集进行整理,最终从小程序平台获得4752条有效音频数据(1.36h),从“真鸟囝”团队处获得已标注数据3845条(1.12h),共计2.48h。使用随机抽取的方式划分,训练集、验证集、测试集数量比例为7097 : 1000 : 500。
按照与预训练建模时相同的方法进行参数配置,首先测试分别从头开始训练两种编码器算法的语音识别模型的性能,再在启动ESPnet模型训练脚本时增加预训练模型路径参数(pretrained_model)以导入模型进行参数初始化,测试微调工作下两种编码器算法的语音识别模型性能。最终得到四种不同训练方式产出的模型。实际训练时发现部分模型经过近30次迭代于训练末期附近仍在提升性能,故增大迭代次数至60次。
4.3.2 训练结果
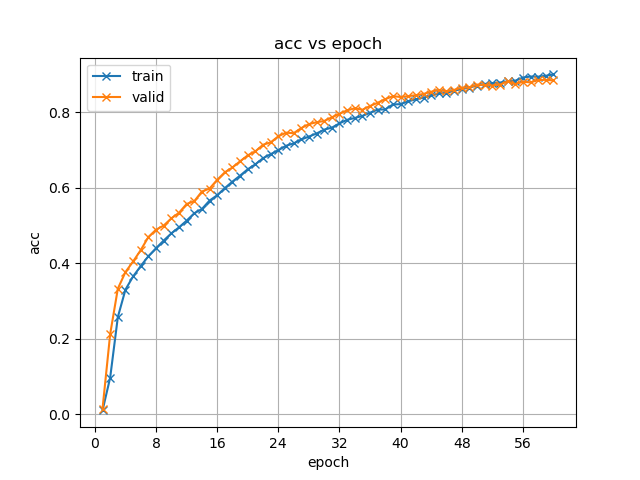
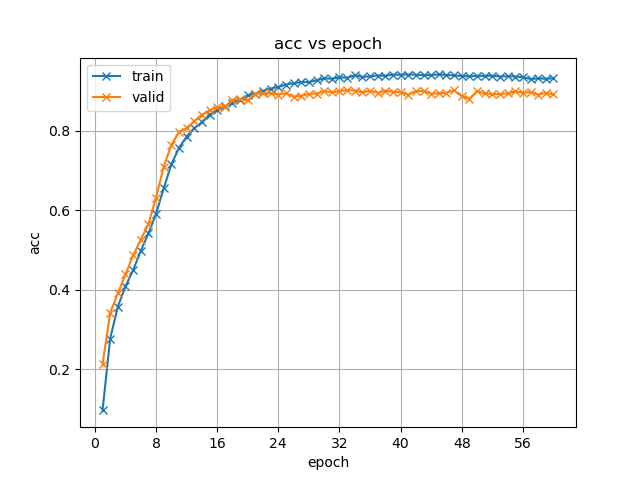
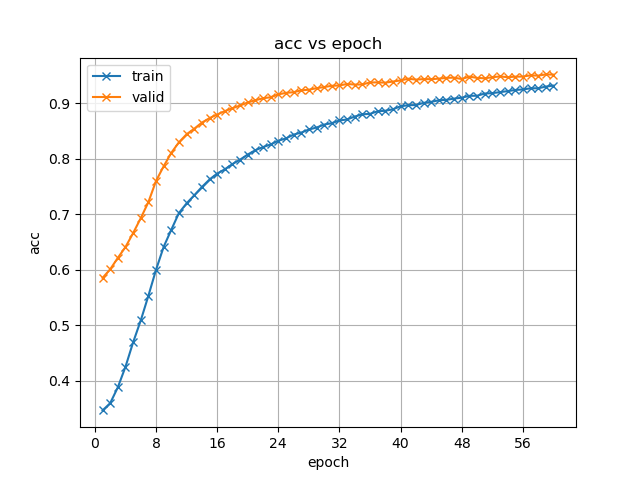
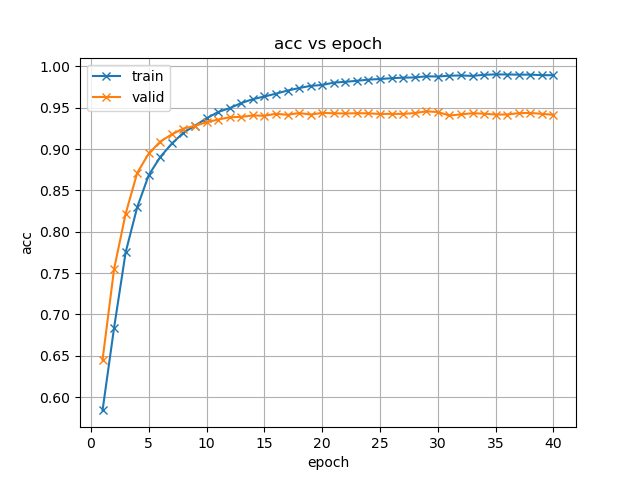
图 4.3 不同模型训练策略下准确率(acc)随迭代次数的变化
组图 4.3展示了不同模型训练策略下准确率虽训练迭代过程的变化,这里的准确率性能实际意义上可等价衡量模型的字错率性能。
首先分析两种编码器使用迁移学习方法训练得到结果的共性:(1)起步性能提升:原先模型训练的准确率都是从0附近开始变化,加入预训练模型初始化参数后验证集下的起步性能就已有60%左右;(2)收敛速度加快:观察准确率变化曲线拐点或对比等准确率大小对应的迭代次数,可以看到加入预训练模型微调后模型更早出现了收敛趋势,这也与起步性能提升有直接关系;(3)收敛性能更好:加入预训练模型微调后模型曲线所示的性能上限均较从头开始训练方法有提升。
接着分析两种编码器算法各自的表现特点:(1)收敛特性: Branchformer模型在前10次迭代过程中迅速收敛,而后出现拐点,并迅速出现训练集准确率结果上升而验证集性能增长停滞的情况,这说明模型已经达到性能瓶颈,这种瓶颈既可能是来自模型自身的过拟合,也可能是数据集本身的质量问题,现有情况下语音和标注转写的质量不够高,错误较多,阻碍了模型学习。Transformer模型收敛过程平缓,尚未出现类似的情况。(2)收敛效果:从图表和实际训练日志所示,两类模型最终在验证集上的性能表现差异不大。但结合收敛特性,可认为Branchformer模型的训练效率更高。
表 4.2 不同训练策略所得模型性能测试结果
字错率 CER (%) | 词错率 WER (%) | |
Transformer 编码器 | 13.5 | 54.9 |
Transformer 编码器+微调 | 7.3 | 29.1 |
Branchformer编码器 | 8.4 | 32.6 |
Branchformer编码器+微调 | 7.3 | 29.5 |
在测试集上以字错率和词错率定量评估不同训练策略得到的模型的性能,如表 4.2所示。可以看出,不同模型结构下引入微调的迁移学习各自均可提高模型性能,尤以使用Transformer编码器的模型提升效果最明显,字错率和词错率分别降低了6.2%和25.8%。同时,迁移后的两种编码器模型在性能上的差异已被消弭,原先性能更好的Branchformer模型甚至在词错率指标上相较Transformer模型略有逊色,这在某种程度上支持了上文提到的过拟合假设。
结合上述实验结果,可得到以下结论:(1)迁移学习技术能够有效提高低资源汉语方言语音识别模型构建效率与最终性能;(2)低资源条件下对模型编码器层面的算法改动对迁移学习产出结果的实际性能影响不大。
4.4 本章小结
本章主要是对语音识别工作各个模块的实现方法进行详细说明,展示了语料收集平台的实际运行效果,比较分析了预训练和迁移学习方法在不同编码器模块下的训练过程特征以及产出模型的性能。实验结论肯定了迁移学习方法对模型性能的提升效果,并指出编码器层面的模型修改无法为模型性能优化做太多贡献。
5 模型改进
5.1 改进思路
前文的实验工作指出编码器模块的算法调整未能对最终结果明显有利的影响。同时在语音识别工作各个环节模块的功能解释上,编码器主要承担音频数据的人类语音声学特征提取工作,这部分工作从当前语音语言学相关的理论来看实际可调节和扩展的思路并不多。与之相对的,解码器模块因其更关注文本序列间的关系,具有更大的可操作空间。
5.2 双向注意力与重打分
ESPnet框架所用混合CTC/Attention结构中各个解码功能模块独立运行,并对各自的结果进行加权汇总得到预测结果。这其中注意力解码器模块只能运用上文一预测的序列信息结合整个音频特征对目标序列进行预测,无法利用当前时刻之后的下文信息帮助推导,因为该结构中没有任何一个模块可以提前告知或得出后续的预测结果给其他解码器。从语言学上的观点以及日常语言使用的实际感知分析,说话内容序列的后文信息对推导前文是有帮助的,尝试实现音频数据上下文信息的全面提取应当有助于在低资源语料条件下充分利用语音数据。
本文参考WeNet2.0开源语音识别工具[14]的实现思路,结合实际特点,在ESPnet原有框架上对建模结构进行调整,实现了双向注意力解码器与重打分机制。从而在模型训练与解码过程对音频上下文整体信息的提取。
标准的Transformer解码器会在训练时候对输入的目标序列进行从左到右的掩码操作(left-to-right mask)来限制当前时刻只能看到之前的信息,主要是为了保持预测时和训练时信息量一致,保证输出结果的一致,同时适配并行计算,提高可解释性。如果要提取后文信息,可以在标准的Transformer解码器基础上改动掩码操作,使得用于注意力计算的输入目标序列包含当前时刻之后的信息,以此指导模型训练优化。
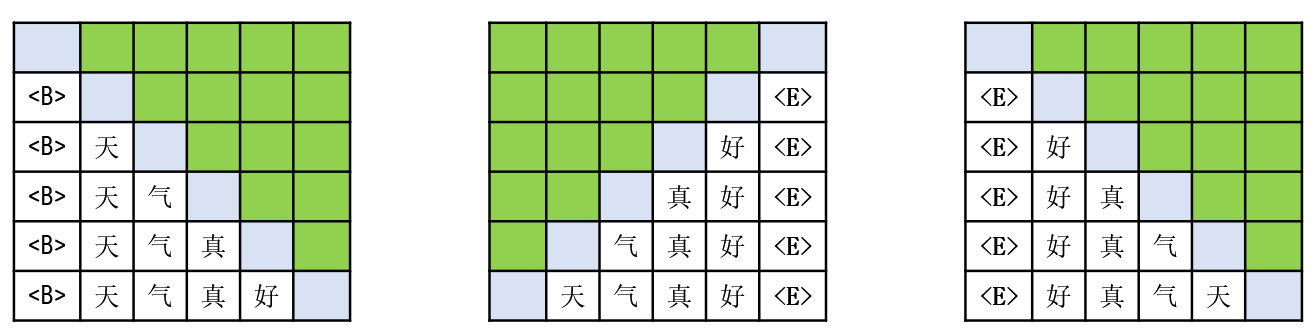
(a)标准L2R掩码方式 (b)更改掩码方法为R2L (c)另一种等价的R2L实现
图 5.1 不同解码器算法的掩码操作示意
组图 5.1对该方法进行了原理展示,图中绿色部分为被掩码操作遮盖的信息,蓝色部分为当前时刻需要预测的信息。每个子图矩阵虽在训练过程中是并行计算,但也通过从上到下的各行差异反映了实际解码时生成预测序列的动态流程。如图 5.1(a)标准流程
就是从左到右生成“<B>天气真好<E>”语句(<B>、<E>分别代表序列起始和终止符号),推理解码时每生成一个字后就把之前生成的内容一并提交给后续注意力层进行解码,序列之后的内容在训练时被掩码操作隐藏起来,在实际推理中则是未知的。简单来说就是需要只利用语音特征和“<B>天气真”这些信息来推出“好”字。
而按图 5.1(b)进行修改掩码方法后,解码器工作变为使用语音特征和“气真好<E>”这些信息推出“天”字。从而实现从右到左利用后文信息进行学习的目的。该改动方法需要在Transformer解码器内部对掩码操作层进行调整,WeNet2.0则提供了一种更为快捷的方法:将输入序列倒序。如图 5.1(c)所示,不改变原本的掩码方法,而是将训练时输入的目标序列倒序,现在需要解码器使用语音特征和“<E>好真气”来推出“天”字了。从上到下来看整个矩阵,可以发现其输入的信息量没有发生变化,只是信息位置发生了统一调整,这同样是在从右到左学习后文信息,而解码器最终的输出也将是倒序的。同时,WeNet2.0的测试表明这两种从右到左(R2L)注意力解码器实现方式的性能接近。由此得到了一种新的注意力机制解码器,称R2L解码器,将R2L解码器引入到ESPnet原有的模型架构中与原有标准模型的L2R解码器共同参与训练,就能实现双向的注意力机制的模型学习。更好地利用数据集信息。
修改模型架构后需要适应性修改模型推理相关方法,因为R2L解码器生成的是倒序文本,无法直接参与到其他模块(CTC和原有的L2R解码器)的加权评分、波束搜索工作中。这里使用一种在ESPnet下容易实现的重打分方法解决该问题:对原有模块的加权评分、波束搜索后输出的候选项序列内容倒序,将倒序后的序列依次在R2L解码器内进行重新评分,对评分结果与原有模块的评分值加权求和。得到最终的候选序列并输出最优结果。
5.3 模型结构
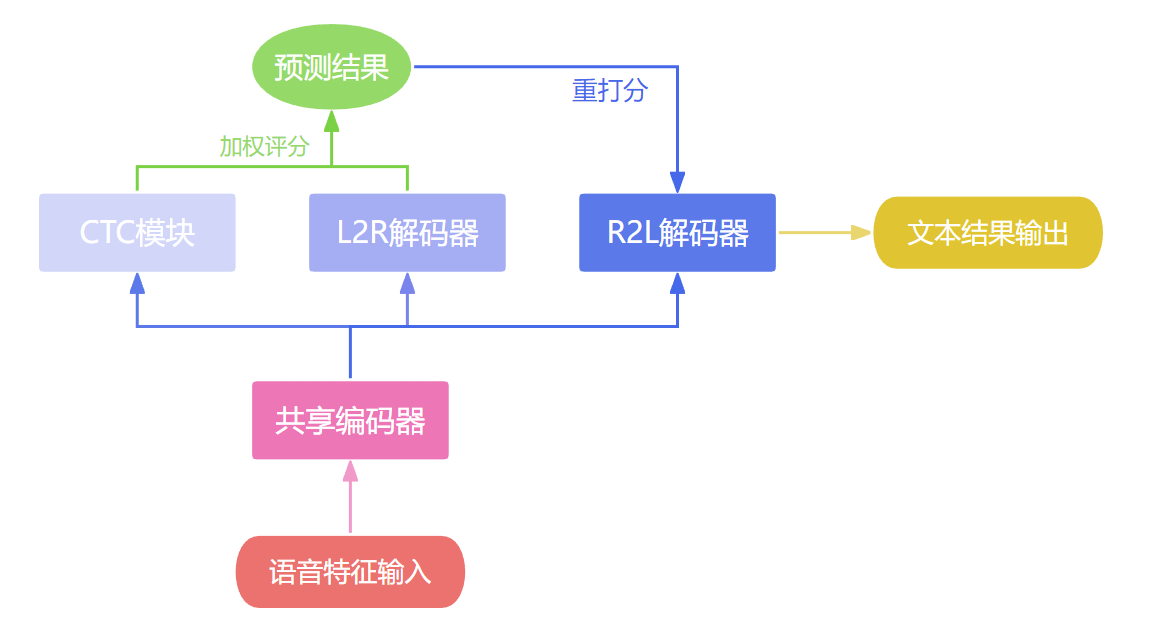
按照上一节的改进方法描述,可将ESPnet原始的模型框架(图 2.4)修改得到如图 5.2所示的一款使用混合CTC/双向注意力结构的语音识别模型。
5.4 算法实现
依据前文所述双向注意力机制算法思想,再此对ESPnet模型构建、训练、解码功能的源码调整方法进行。
- 在源码的模型构建任务部分(espnet/espnet2/tasks/asr.py/ASRTask/build_model)
- 仿照原有的decoder配置,额外定义一名为decoder_R2L的解码器模块,用以之后实现从右向左注意力机制的解码器。并以形如可选参数的写法加入模型构造函数的调用中。
- 在源码的模型定义部分(espnet/espnet2/asr/espnet_model.py/ ESPnetASRModel/)
- 仿照原有的decoder定义,完成decoder_R2L 的定义与记录。同时,在构造参数处仿照ctc_weight的格式,增加一名为参数att_r2l_weight,用以控制双向注意力模块计算损失函数时的权重。
- 于注意力解码器分支处,仿照原有decoder调用方式,调用注意力机制解码器运行、评分、计算损失的函数_calc_att_loss(),在这个函数内完成了从右向左注意力解码器的实现。主要工作是对原有的标注序列张量ys_pad真正包含信息的部分进行倒置和覆盖。其大致过程的伪代码如下方算法1:
算法5.1: 注意力解码器的调度运行
输入: 编码器输出序列encoder_out, 编码器输出序列长度encoder_out_lens, 经过填充的标注序列ys_pad, 标注序列长度ys_pad_lens,注意力解码器模块decoder
输出: 解码器输出序列 decoder_out.
1: if TYPE(decoder) == “ R2L” :
2: for index in [ 0 : LENGTH(ys_pad) ]:
3: tokens_pad = ys_pad [index] #当前填充标记序列
4: tokens_length = ys_pad_lens [index] #当前标记序列真实长度
5: ys_pad [index] =REVERSE(tokens_pad [:tokens_length]) + tokens_pad [tokens_length:] #翻转标记序列位置,填充位置内容不变
6: end for
7: end if
8: ys_in_pad, ys_out_pad = add_sos_eos(ys_pad) #分别增加开始和结束标记
9: ys_in_lens = ys_pad_lens + 1
10: decoder_out, _ = decoder(encoder_out, encoder_out_lens, ys_in_pad, ys_in_lens) #调用forward函数解码得到序列评分矩阵
11: ……(省略计算acc, cer, wer的调用过程)
- 任务参数解析部分(/espnet/espnet2/tasks/abs_task.py/AbsTask/get_parser)
增加两个参数att_r2l_infer_weight、rescore_r2l_max,分别用于控制解码推理时R2L解码器重评分的权重,以及解码推理时R2L解码器重评分过程所取的预测结果数量。
- 模型推理部分(/espnet/espnet2/bin/asr_inference.py/Speech2Text/__init__)
为BeamSearch波束搜索函数构造传参时增加上述两个参数作为同名可选参数,同时也将来自模型结构中的decoder_R2L一并传参。
- 波束搜索解码部分(/espnet/espnet/nets/beam_search.py/BeamSearch/)
在其__init__构造函数下适配新传入的三个参数。在其forward函数下实现重评分机制,其实现方法如下方算法5.2所述。其中限制重评分次数是为了降低重评分过程中的时间开销,只取候选结果中评分最优的几个进行中重评分筛选。评分权重att_r2l_infer_weight在实际测试中简单地设为0.5。
算法5.2: 候选结果重打分
输入: 波束搜索候选结果end_hyps , R2L解码器重评分权重att_r2l_infer_weight,重评分候选结果提取个数 rescore_r2l_max, R2L注意力解码器decoder_R2L
输出: 重评分后的候选结果列表hyps_hyb.
1: nbest_hyps = sorted(ended_hyps, key=lambda x: x.score, reverse=True) #优先选取评分最高的候选结果
2: if att_r2l_infer_weight != 0.0:
3: hyps_R2L = []
4: hyps_hyb = []
5: cntR2L = 0 #累计重评分次数
6: for hyp in nbest_hyps:
7: cntR2L += 1
8: if cntR2L > rescore_r2l_max:
9: break #限制重评分次数
10: end if
11: hyp_yseq_R2L = torch.flip(hyp.yseq, dims=[0]) #倒转当前候选结果序列
12: score = 0
13: for index in range(hyp.yseq.shape[0]-1): #遍历该结果序列
14: scores_R2L, _ = decoder_R2L.score(hyp_yseq_R2L[:index+1], None, _)
15: score += scores_R2L[hyp_yseq_R2L[index+1]]
16: #按照当前时刻倒序序列内容评分解码,并累加序列下一个标记对应的评分值。
17: end for
18: hyps_hyb.append(
19: Hypothesis(
20: score = hyp.score * (1 - att_r2l_infer_weight) + score * att_r2l_infer_weight
21: #参照权重设置重新赋予评分
22: yseq = hyp.yseq
23: scores=hyp.scores
24: states =hyp.states
25: ))
26: end for
27: end if
5.5 性能分析
表 5.1 双向注意力机制模型性能测试结果
字错率 CER (%) | 词错率 WER (%) | |
Transformer编码器 | 13.5 | 54.9 |
Transformer编码器+双向ATT | 10.2 | 37.7 |
Transformer编码器+微调 | 7.3 | 29.1 |
Transformer编码器+双向ATT+微调 | 6.6 | 27.3 |
Branchformer编码器 | 8.4 | 32.6 |
Branchformer编码器+双向ATT | 8.1 | 31.9 |
Branchformer编码器+微调 | 7.3 | 29.5 |
Branchformer编码器+双向ATT+微调 | 6.1 | 25.3 |
表 5.1是对改进后模型进行测试的结果与前文建模工作的结果比对,可以看到加入双向注意力机制后,两种编码器结构的模型的字错率、词错率表现均有不同程度改善,以从头训练的Transformer编码器模型加入双向注意力机制后词错率变化最为明显,降低了17.2%。这证明实现双向注意力机制对模型的改进是有效的。
表 5.2 模型泛化性能评估
字错率 CER (%) | 词错率 WER (%) | |
Transformer编码器+双向ATT+微调 | 13.8 | 48.4 |
Branchformer编码器+双向ATT+微调 | 15.5 | 49.5 |
表 5.1所示模型测试结果以Branchformer编码器+双向注意力+微调的结构表现最优,其次为Transformer编码器+双向注意力+微调结构。为验证模型泛化能力,本文增加了一组测试,使用来自语料收集平台的100条福州方言语音标注数据为测试集,这部分筛选的语音数据不仅本身未参与模型训练,其发音人也无任何其他录制的其他数据参与过训练环节。这意味着对于模型来说是一个全新的发音人音色,象征着实际应用中真实大众的口音。
该补充实验的结果展示在表 5.2,有趣的是在测试集中表现最佳的Branchformer相关模型在泛化测试中字错率和词错率表现都微弱于Transformer相关模型。这说明Branchformer模型确实有比Transformer更强的过拟合倾向,在低资源条件下的语音识别建模工作应重视此类模型的过拟合问题,寻找合适的解决方法。综合上述实验结论,本文最终决定以Transformer编码器+双向注意力+微调结构训练得到的模型作为实用平台的部署模型。
5.6 本章小结
本章主要介绍了对ESPnet现有模型框架的改进措施,详细介绍了双向注意力机制和重打分方法原理,并以此指导源码级别的修改工作,最终成功进行了新模型的训练测试,获得了较为理想的性能指标改善。同时还针对模型泛化能力专门设计了实验进行量化评估,得到了有效结论,最终选取Transformer编码器+双向注意力+微调模型用于下一步模型部署平台的应用。
6 模型部署
6.1 设计思路
为实现模型快速部署体验,本文直接基于语料收集平台的小程序前后端进行功能增设。利用构建好的模型实现福州方言语音查词典功能。
前端增加一个体验界面,用户可以上传录音请求识别。这部分功能与录音上传贡献相类似,可以直接大部分代码。同时,小程序整个生命周期内只能有一个全局录音管理组件,这要求协调好与原有录音界面的关系,避免相互影响。
后端因为基于Python,可直接借助ESPnet相关库函数便捷调用模型。在Web服务程序内收到用户上传的语音后首先将音频转码成需求的格式(16kHz的wav波形文件),再输入到模型中,得到识别结果。随后将结果与现有文本语料库的词汇榕拼数据比较,逐个进行字符相似度评分(同样使用编辑距离),按评分大小排序,返回识别结果以及语料库中相似度评分最高的数个条目信息。这里的相似度评分需要对识别结果的声韵和声调分别计算并加权求和,因为声调包含的语言信息较少(在福州方言连读变调后尤为如此),故应使声调的权重较低。
前端需要正确渲染返回的内容,向用户展示识别结果。
6.2 设计结构
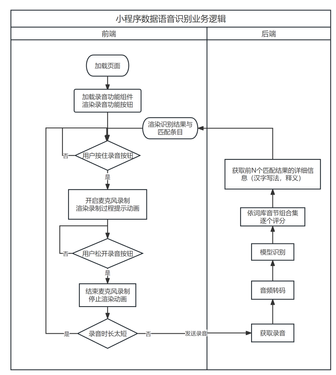
图 6.1展示了语音识别模型部署应用的基本业务逻辑。其中录音按钮的行为不同于语料收集平台的录音上传界面,本界面下当监听到录音按钮松开事件时会自动尝试上传语音获取识别结果,不额外增设其他按钮,这更符合实际应用场景。
6.3 效果展示
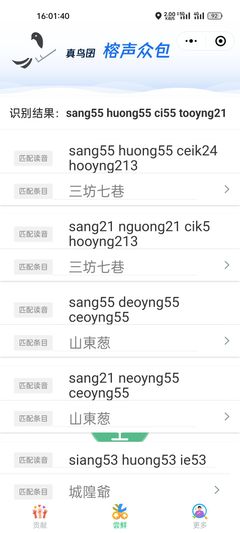
图 6.2展示了实机运行效果,目前模型部署平台已能够正确配合后端执行预期功能,模型输出结果正常。经多名志愿者反馈,识别结果准确率已达堪用水准。这说明本设计的所实现一整套语料收集、模型训练、部署应用系统是切实可行的,具有实际利用价值。

结论
本文研究了端到端模型语音识别的主流算法,并通过结合迁移学习的微调技术,在粤语语料库和福州方言数据集上进行了多种算法结构的建模测试,对使用迁移学习进行低资源汉语方言语音识别工作的可行性、有效性进行了验证。同时结合目前语音识别算法前沿,对ESPnet工具原有的建模方式进行改进,设计了混合CTC/双向注意力机制的基础模型,配合迁移学习工作,取得了优于原有建模基准性能的表现。上述工作填补了汉语方言间跨语言迁移学习研究领域的空白。
与此同时,本文充分完善了语音识别任务的周围工作,自行搭建了一套便捷高效的语料收集与校注小程序平台,同时完成了模型的部署实用。该部分工作具有很强的实际应用价值,对今后进一步的学术工作研究、方言保护事业以及社会商业应用等领域都具有较好的可承接性。
本文工作未来的展望包括:
(1)进一步加大迁移学习源语言、目标语言的语料库规模,测试汉语内部跨语言构建大型预训练模型的性能与迁移学习效果;
(2)测试其他如带部分结构冻结的微调、适配器结构等迁移学习手段对语音识别建模性能的影响;
(3)从汉语音系共通特征的角度发掘模型结构的可优化项,如存在于整个音程中的声调特征等;
(4)尝试引入半监督或无监督方法为低资源汉语方言语音识别建模寻找解决方案。
语音识别工作在可观的一段时间内仍然会是计算机科学领域自然语言处理相关技术的研究热点,并伴随着人工智能技术的进化而不断迭代。相信在不远的将来,低资源语言下的语音识别工作能够取得显著进展,让世界上的更多的小语种和方言使用群体感受到先进科学技术带来的便利。
参考文献
- Watanabe S, Hori T, Karita S, et al. Espnet: End-to-end speech processing toolkit[J]. arXiv preprint arXiv:1804.00015, 2018.
- Hou W, Zhu H, Wang Y, et al. Exploiting adapters for cross-lingual low-resource speech recognition[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021, 30: 317-329.
- 海拉罕. 喀尔喀蒙古语声学模型研究与语音识别系统实现[D].内蒙古大学,2022.DOI:10.27224/d.cnki.gnmdu.2022.001590.
- 杨学斌. 低资源的维吾尔语语音识别系统设计与实现[D].西北民族大学,2021.DOI:10.27408/d.cnki.gxmzc.2021.000146.
- 陈紫艳. 基于深度学习的彝语语音识别的研究[D].西北师范大学,2021.DOI:10.27410/d.cnki.gxbfu.2021.000146.
- 但扬杰. 基于注意力和迁移学习的汉语方言识别研究[D].江西师范大学,2021.DOI:10.27178/d.cnki.gjxsu.2021.000354.
- Xu F, Dan Y, Yan K, et al. Low-Resource Language Discrimination toward Chinese Dialects with Transfer Learning and Data Augmentation[J]. Transactions on Asian and Low-Resource Language Information Processing, 2021, 21(2): 1-21.
- Luo J, Wang J, Cheng N, et al. Cross-language transfer learning and domain adaptation for end-to-end automatic speech recognition[C]//2021 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 2021: 1-6.
- Graves A, Fernández S, Gomez F, et al. Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks[C]//Proceedings of the 23rd international conference on Machine learning. 2006: 369-376.
- Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
- Peng Y, Dalmia S, Lane I, et al. Branchformer: Parallel mlp-attention architectures to capture local and global context for speech recognition and understanding[C]//International Conference on Machine Learning. PMLR, 2022: 17627-17643.
- Watanabe S, Hori T, Kim S, et al. Hybrid CTC/attention architecture for end-to-end speech recognition[J]. IEEE Journal of Selected Topics in Signal Processing, 2017, 11(8): 1240-1253.
- Yu T, Frieske R, Xu P, et al. Automatic Speech Recognition Datasets in Cantonese Language: A Survey and a New Dataset[J]. arXiv preprint arXiv:2201.02419, 2022.
- Zhang B, Wu D, Peng Z, et al. Wenet 2.0: More productive end-to-end speech recognition toolkit[J]. arXiv preprint arXiv:2203.15455, 2022.
致谢
满城的樟香氤氲立夏前的雨声,逸生的薇实将要饱满,黄栀的碎瓣正勾勒上弦月的底色,还未到它痛快染香的旬候。清越的虫鸣打破灰绿色的拂晓,窗外斑鸠的早安陪我写下本科学业进程里最后的几行感慨。
冀以尘雾之微,补益山海;萤烛末光,增辉日月。长期以来我都希望能够将自己所学知识为母语方言保护工作贡献自己微小的力量。承蒙导师的理解与支持,在课题方向选择上给了我极大的灵活自主性。同时我更需感谢导师在实际毕业设计工作中给予的帮助和指导,为我提供了实验平台资源,不厌其烦地对设计细节、实验思路和论文写作批评指点,最终促成了这份设计的顺利定稿。
本文工作是以实际用途为导向的,设计最开始的目的是为福州方言电子词典产品《榕典》增设语音查词功能。其数据收集与平台测试工作离不开各方志愿者的贡献。在此我首先感谢家人的理解和支持,语料收集平台获得的数据有将近一半是来自本人母亲的贡献。同时,与我一同参加福州方言保护志愿工作的前辈在提供音频数据外还对数据标注审核贡献了大量工作,倾注了不少精力。此外仍有不少难以详尽列名的家乡老师和同学、热心语保工作的前辈都在支持我的工作,这些不计回报的贡献一点一滴地在模型训练过程中转化为实际可靠的性能提升。并换回了体验用户对最终的结果产出报的认可和赞赏。
人生何处不遗憾。我本科历程中的每一份“完成”总伴随着会多或少的遗憾,第一份遗憾便是录取专业被调剂。此后的生活与学习亦是如此,我最终既因未能在学业成绩上有出色的表现而无缘推免,亦因学资平平考研复习不足而上岸无望。遗憾是耐人寻味的,像是单行道旁墙沿的缺口,成为一处处可以回味与思量却不能回头填补的空白。尽管如此。遗憾背后的“完成”仍能给予我可感的宽慰。我通过转专业申请回到了第一志愿的专业;在一些课程实验中的工作得到了老师同学的认可;最终完成了本科的全部学业进程,拥有了进入专业领域的一块敲门砖。道阻且长,我将更加努力,用更加平和的方式迎接未来人生节点上更多的“完成”与遗憾。感谢这四年在岳麓山下遇见的人与物,希望湖南大学越办越好。
最后,我向每一位评审论文并提出宝贵意见的老师致以深深的感谢。
- 作者:叶修齐
- 链接:https://notion.siuze.top/article/e3e6ec8a-bde4-4a71-b661-926212346ae1
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。