
type
status
date
slug
summary
tags
category
icon
password
Property
Mar 6, 2024 11:23 AM
Created time
Jan 31, 2024 05:37 PM
本文是《数据挖掘》课程的一份作业,要求如下:
- 了解常见的决策树算法: ID3算法和C4.5
- 熟悉决策树分类的具体步骤和详细过程。
- 对已有的疾病数据实现决策树分类方法。
〇、项目介绍
本代码文档使用ID3,C4.5算法实现了对给定癌症病人组织样本RNA表达量数据集的决策树建立。
一、数据导入
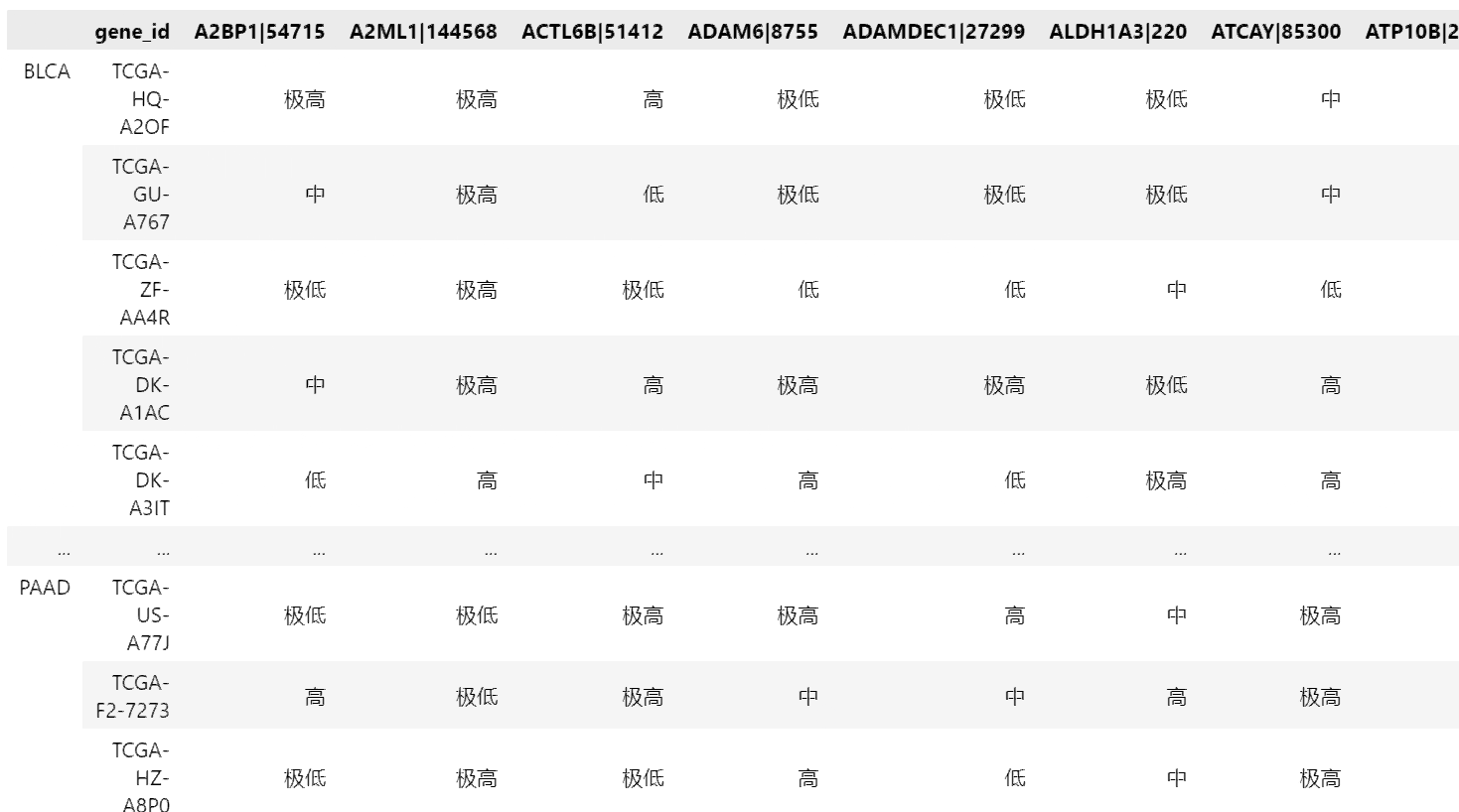
实验要求对已有的疾病数据实现决策树分类方法,这里导入5种癌症的数据,并做调整。
下方得到的MIX数据集的列对应每一种基因的表达量,行对应了不同的病人样本。列表CANCER是所有样本的标签,即该样本对应的癌症名称
二、使用ID3算法生成决策树
2.1 数据离散化
这里使用我上次实验所使用的分箱方法,下面选择(-∞,-1],(-1,0],(0,1],(1,2],(2,+∞)来从小到大表征五种表达量高低程度,实现数据离散化,得到['极低', '低', '中', '高','极高']五种标签值,下面是离散化的实现代码。
2.2 ID3算法的实现
ID3算法的实现中利用递归计算信息增益,按照决策树的返回结构得到被选出的特征属性。
2.3 ID3算法决策树的构建
下方按顺序输出建树时选取的基因
2.4 决策树的可视化

三、使用C4.5算法生成决策树
3.1 C4.5算法决策树的构建
C4.5算法较ID3算法有两大不同,一个是建树特征的衡量指标从信息增益改为信息增益率,另一个是对连续值有了明确的离散化方法,即对连续值特征以某个样本值为分割点进行二分离散化尝试,计算该情形下的信息增益,取能让信息增益最大化的样本值作为选中的离散化分割点。
我尝试对上面的ID3代码进行改写后运行,发现运行缓慢,七个小时后得到结果,考虑其原因是该数据集的特征数量非常多,每建立一个节点就需要对三千多个特征进行分裂点测试,逐个计算信息增益,效率很低。
不久但是又发现信息增益率计算代码有问题,重新跑一次太浪费时间。
随后又在网上寻找其他开源项目测试,企图提高效率,下面使用一个名为ChefBoost的开源包进行测试,
ChefBoost是一个轻量级的Python决策树框架。它涵盖了常规的决策树算法:ID3、C4.5、CART、CHAID和回归树;还有一些先进的技术:梯度提升、随机森林和adaboost。在其使用说明中有标注可进行并行加速。
运行11个小时后仍未出结果,遂放弃。
C4.5在建树的时候不会删除已经被选中过的连续值属性,因此每一次寻找最佳属性都将计算三千多种属性(基因)乘以两千个样本点的分裂情形,时间开销相当惊人。
不得已我最后选取了前面ID3算法所选取的几个属性进行决策树构建,结果如下:
运行时长约两分钟,该工具库还对生成的决策树进行了评估,准确率均为100%。
上述代码运行结果会自动保存在./outputs/rules/下,保存有json格式和if_else条件语句格式,为方便观察,下面对其进行可视化
3.2 C4.5决策树的可视化
将所保存的json读取并转为嵌套字典

四、算法结果的比较


可以看到ID3算法得到的决策树深度要较C4.5小得多,一方面是由于ID3下对连续值进行了离散化,得到的是多叉树,更加扁平,同时离散化也变相平滑了数据,进一步降低了决策树的复杂性。
C4.5计算得到的决策树在深度6~7处存在一个阶梯,该阶梯处也存在较多叶子结点,这与ID3算法的深度是类似的。后续的树形存在变窄(树枝只会朝着一侧分枝)的趋势。虽然C4.5算法决策树在本数据集中的精确度验证达到了100%,但较大的深度下较窄的树形也说明其应当存在过拟合的问题,需要进行剪枝和限制。
- 作者:叶修齐
- 链接:https://notion.siuze.top/article/5a80eb52-57e9-4997-b0f9-46e770782819
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。